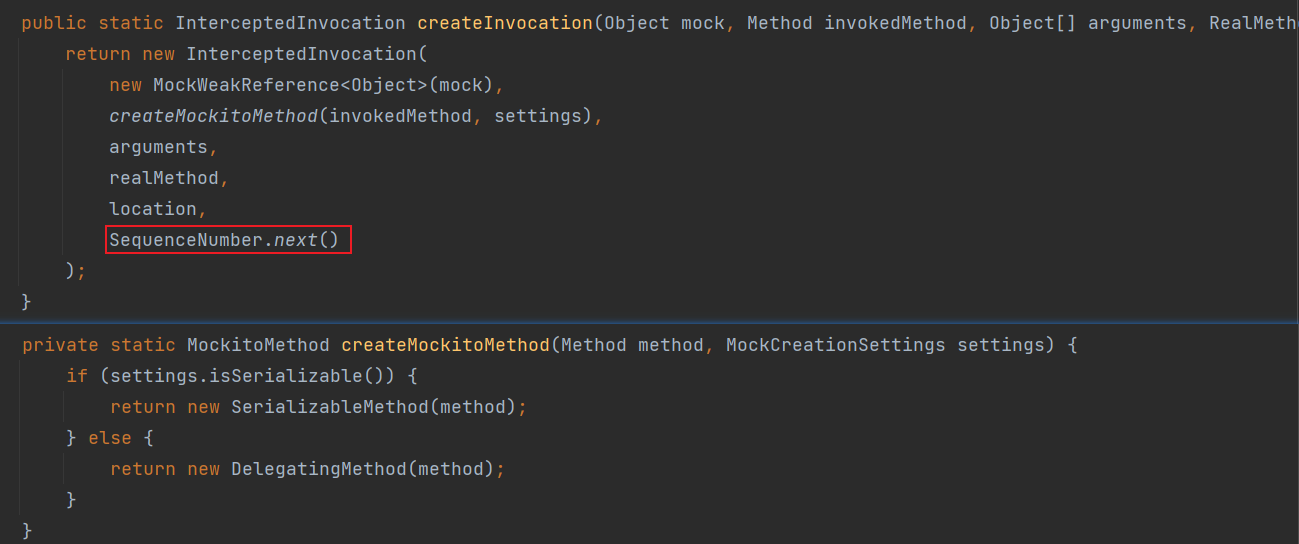
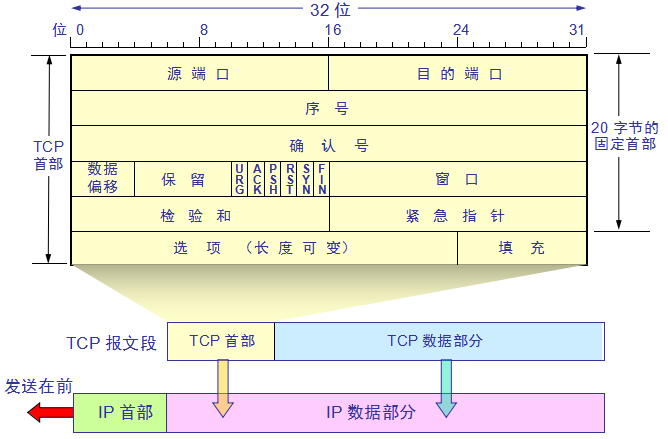
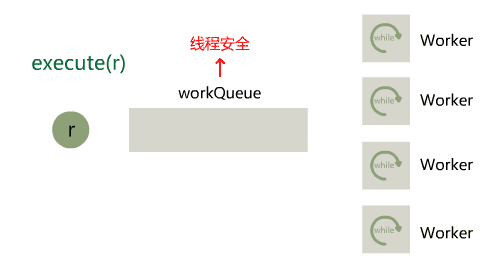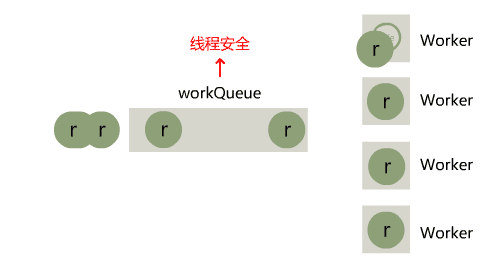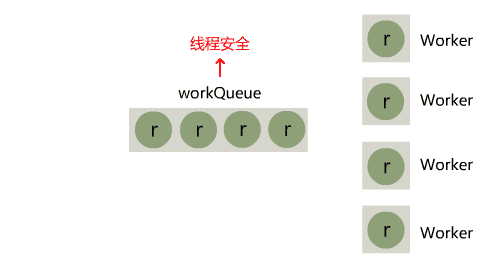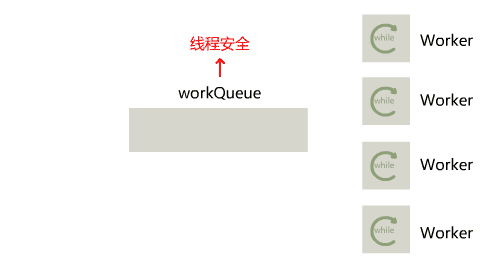
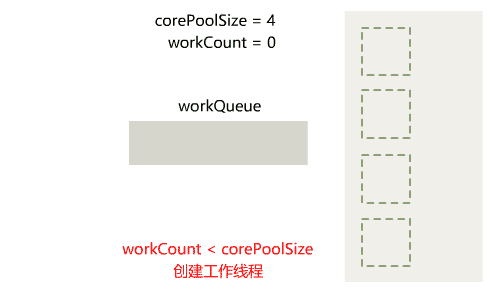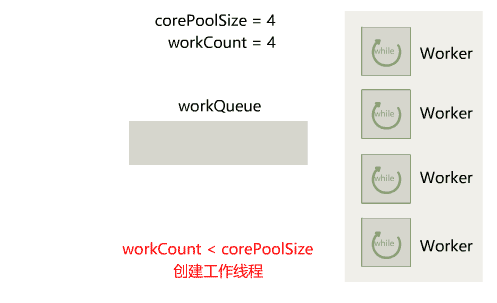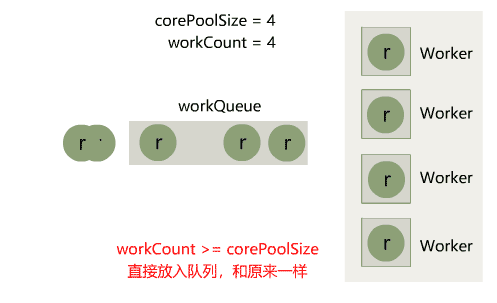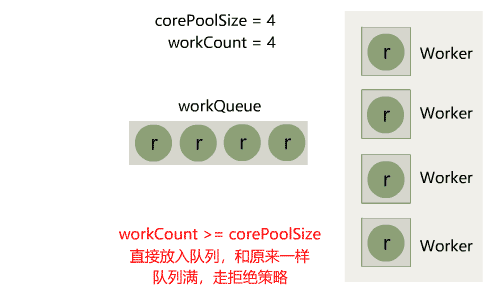
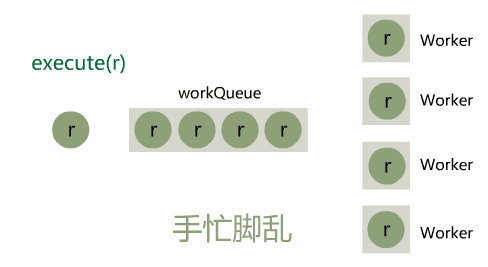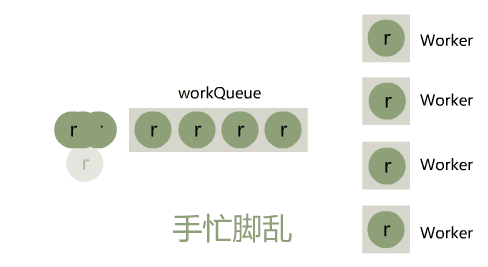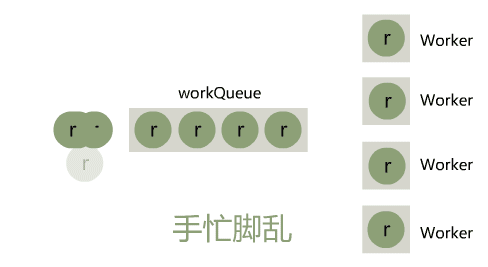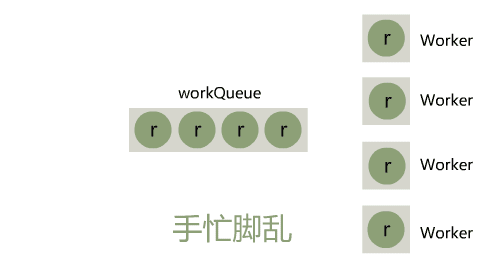
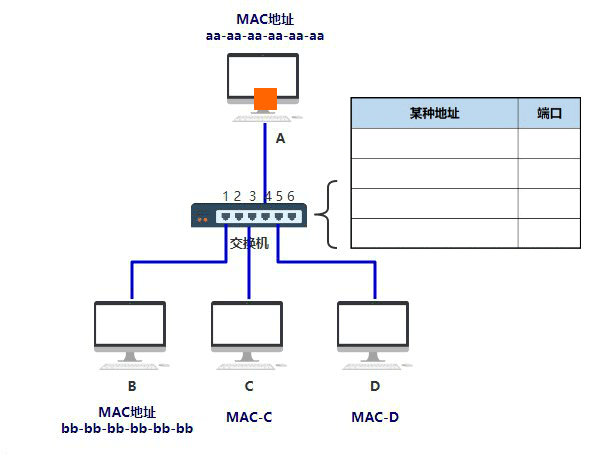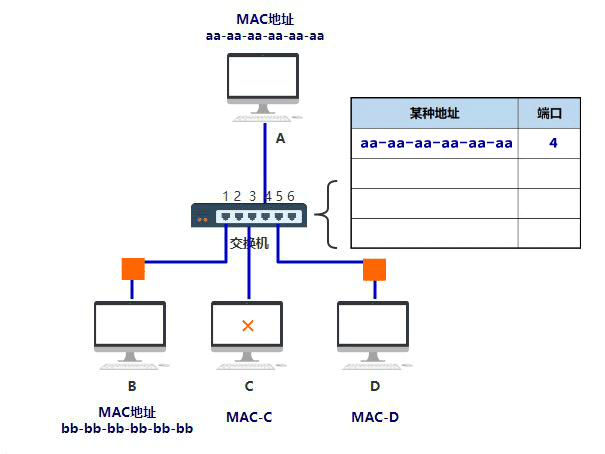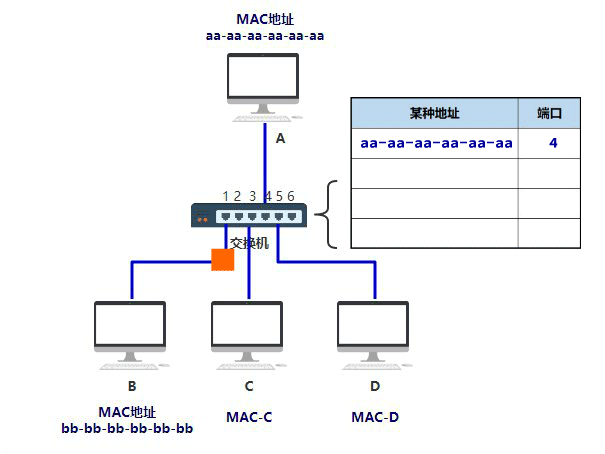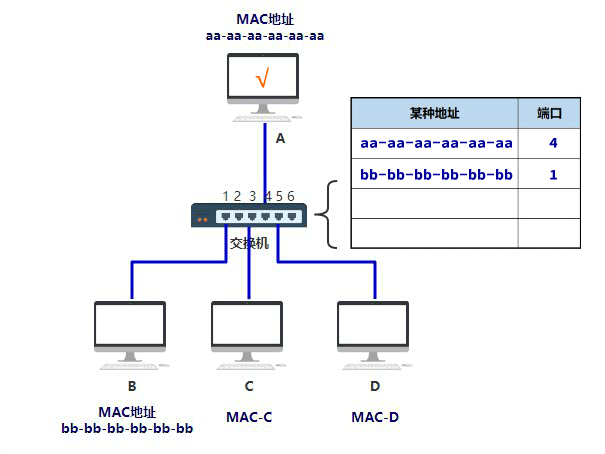
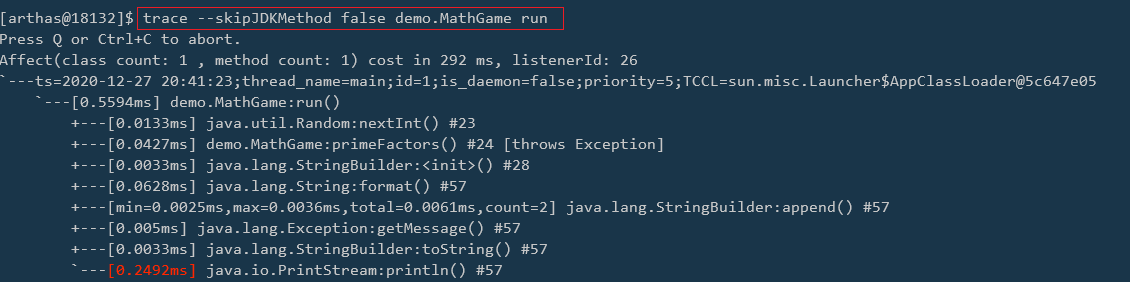
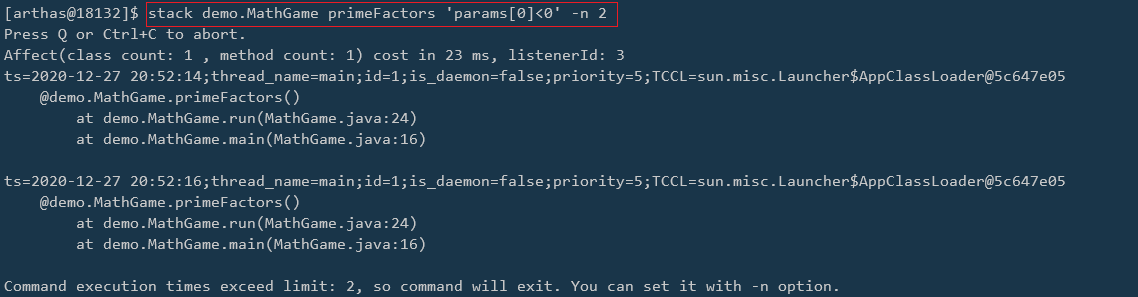
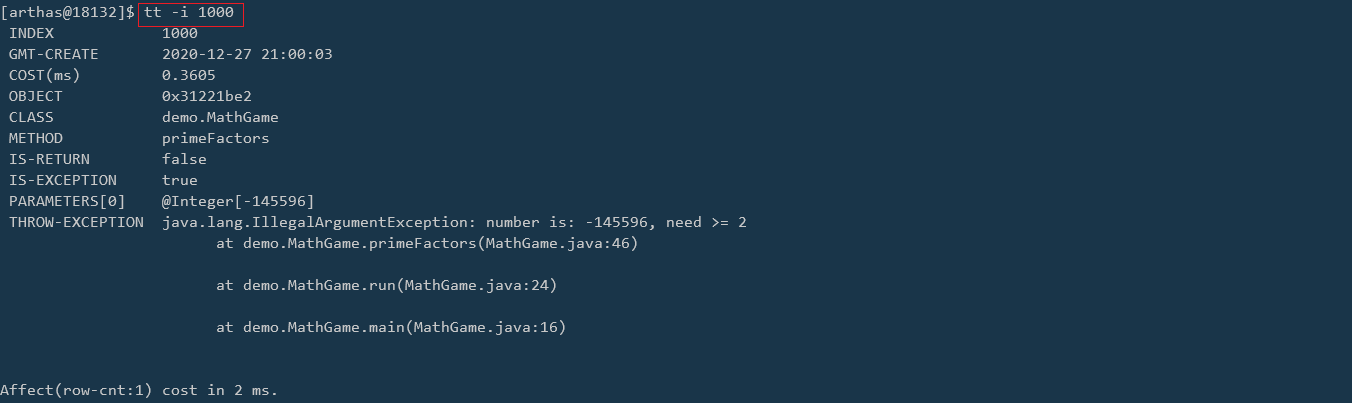
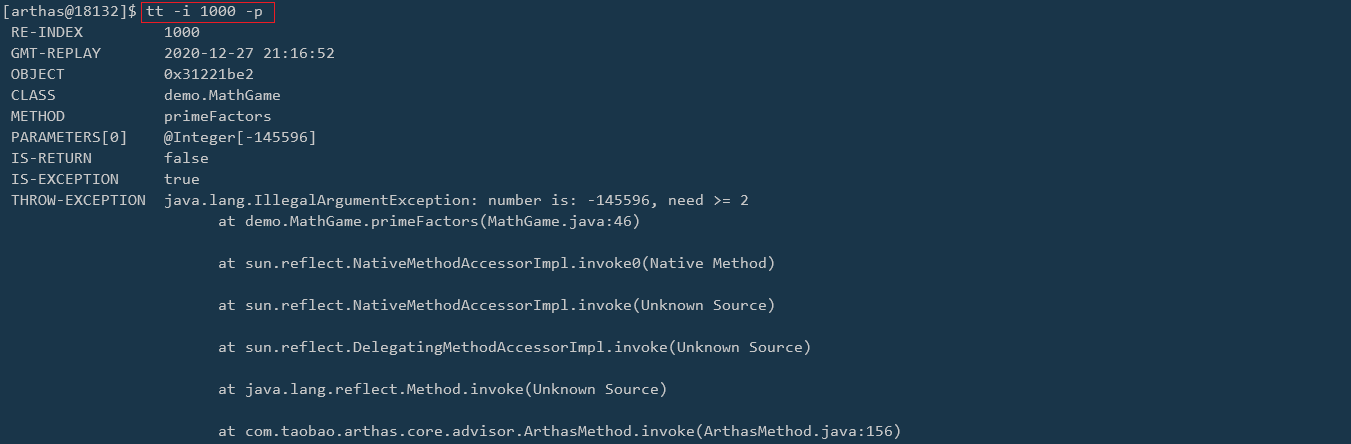
在 Java IO 中,最为核心的一个概念是流(Stream),面向流的编程,一个流要么是输入流,要么是输出流,不可能同时既是输入流又是输出流。
在 Java NIO 中,我们是面向块(block)或是缓冲区(buffer)编程的。Buffer本身就是一块内存,数据的读写都是通过 Buffer 来实现的,还提供了对于数据的结构化访问方式,并且可以追踪到系统的读写过程。
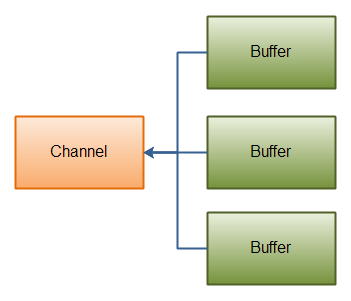
NIO 的核心是由 Channel、Buffer、Selector 三部分组成。
1.1 Channel
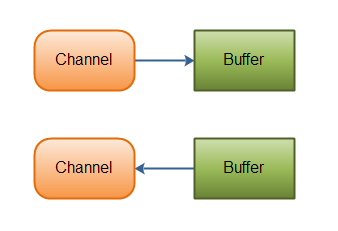
你可以将 Channel 理解成 IO 中的 Stream,数据可以从 Channel 读到 Buffer 中,也可以从 Buffer 写到 Channel 中【对 channel 的读写操作,必须要通过 Buffer 来进行,不能直接从 Channel 读写数据】。
和 Stream 相比又有一些不同:
- Stream 的读写是单向的,而 Channel 是双向的:既可以从 Channel 中读取数据,又可以写数据到 Channel
- Channel 可以异步地读写
- Channel 中的数据总是要先读到一个 Buffer,或者总是要从一个 Buffer 中写入
常见的 Channel 实现有以下几种:
FileChannel: 从文件中读写数据DatagramChannel: 能通过 UDP 读写网络中的数据SocketChannel: 能通过 TCP 读写网络中的数据ServerSocketChannel: 可以监听新进来的 TCP 连接,像 Web 服务器那样。对每一个新进来的连接都会创建一个 SocketChannel
1.2 Buffer
Java中的七种原生数据类型都有各自对应的 Buffer 类型,如 IntBuffer、ByteBuffer 等(除 BooleanBuffer)。使用 Buffer 读写数据一般遵循以下四个步骤:
- 写入数据到 Buffer
- 调用
flip()方法 - 从 Buffer 中读取数据
- 调用
clear()方法或者compact()方法
当向 Buffer 写入数据时,Buffer 会记录下写了多少数据。一旦要读取数据,需要通过 flip() 方法将 Buffer 从写模式切换到读模式。在读模式下,可以读取之前写入到 Buffer 的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用 clear() 或 compact() 方法。
clear()方法会清空整个缓冲区compact()方法只会清除已经读过的数据,任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面
1.3 Selector
Selector 允许单个线程处理多个 Channel。如果你的应用同时建立了多个客户端连接,但是每个连接流量都很低(例如聊天服务器),使用 Selector 就能最大程度提高性能。
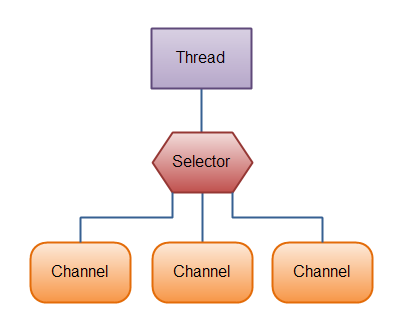
要使用 Selector,得向 Selector 注册 Channel,然后调用它的 select() 方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新连接进来,数据接收等。
二、Buffer
2.1 重要属性
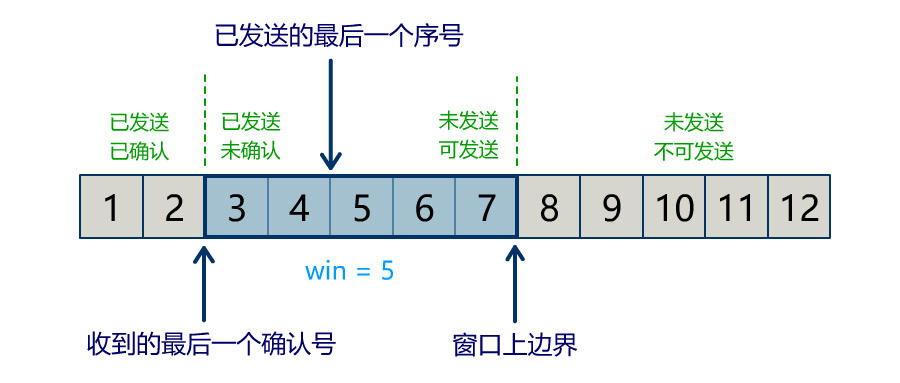
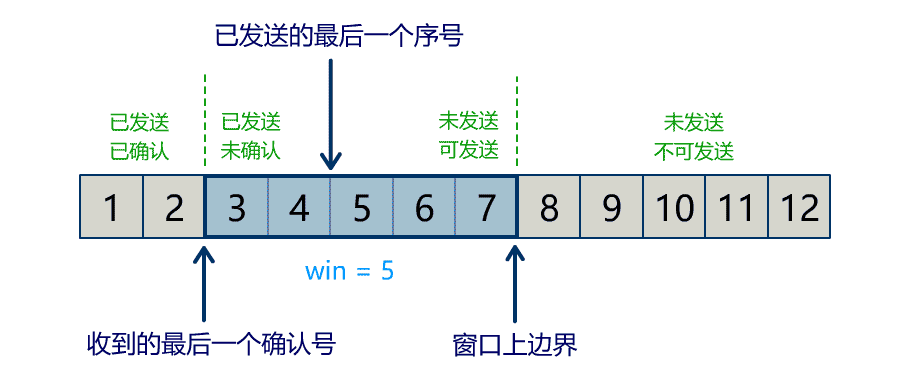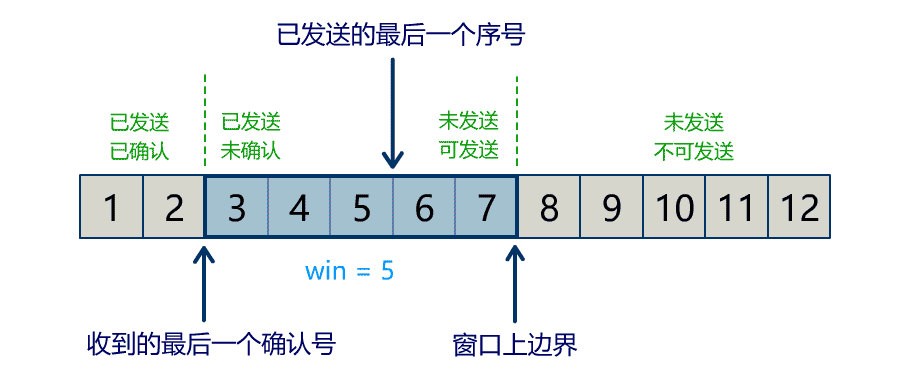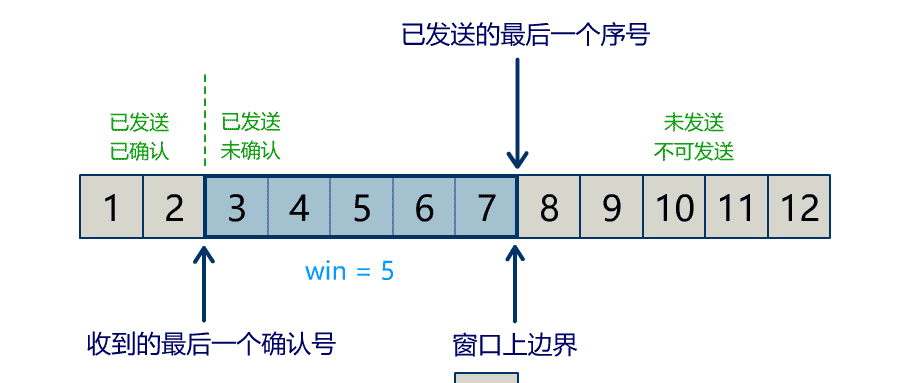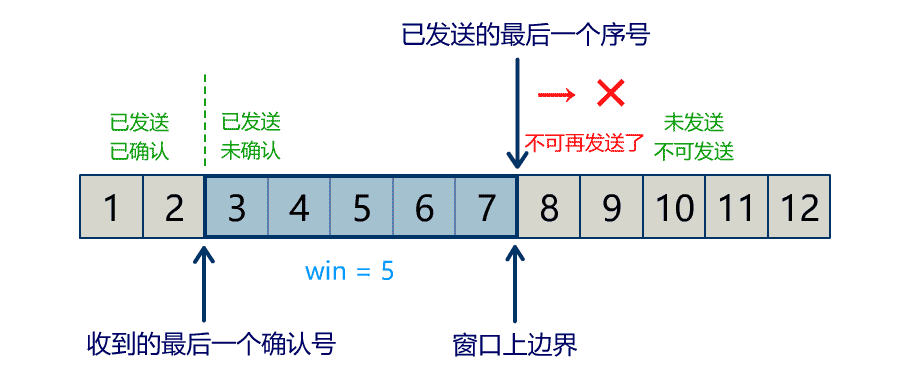
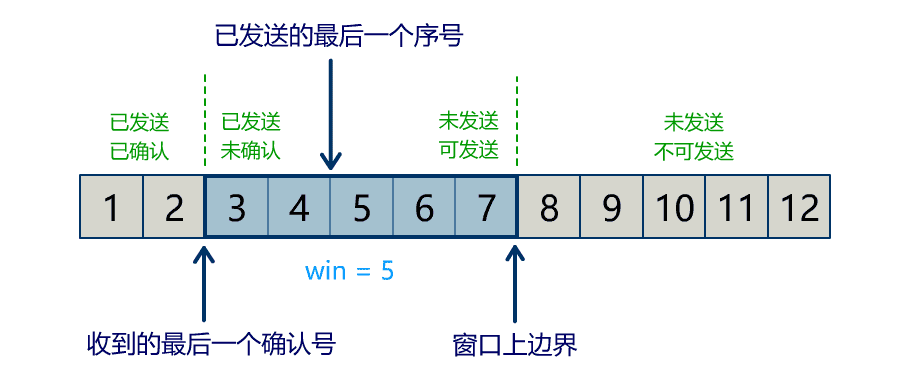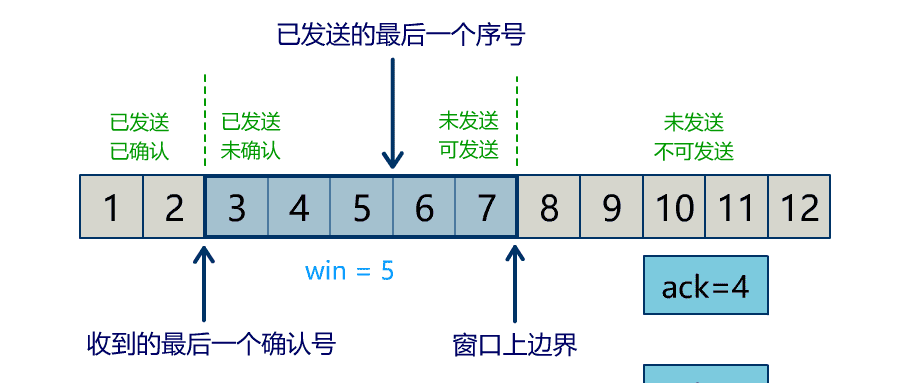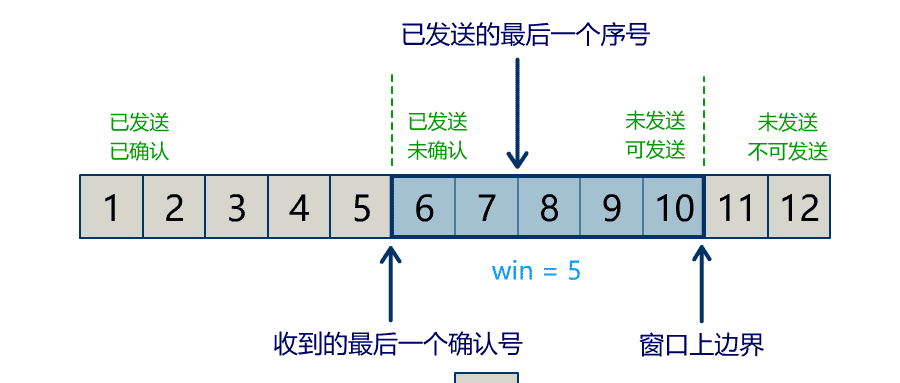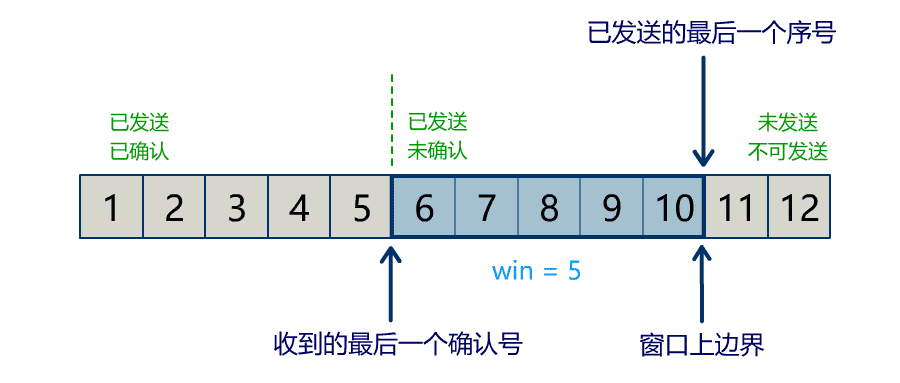
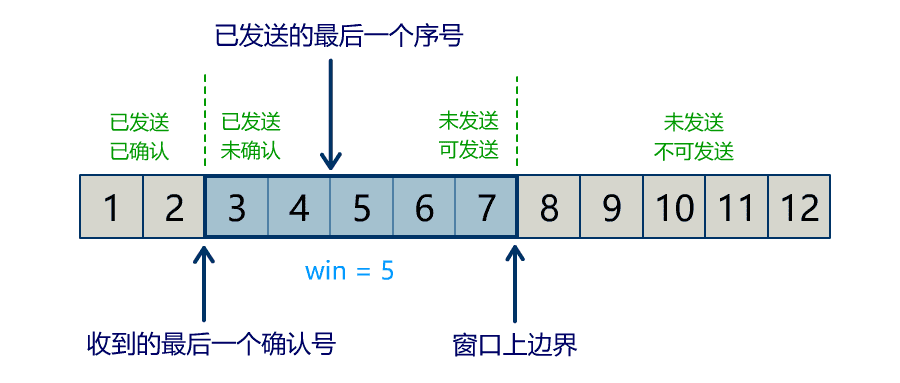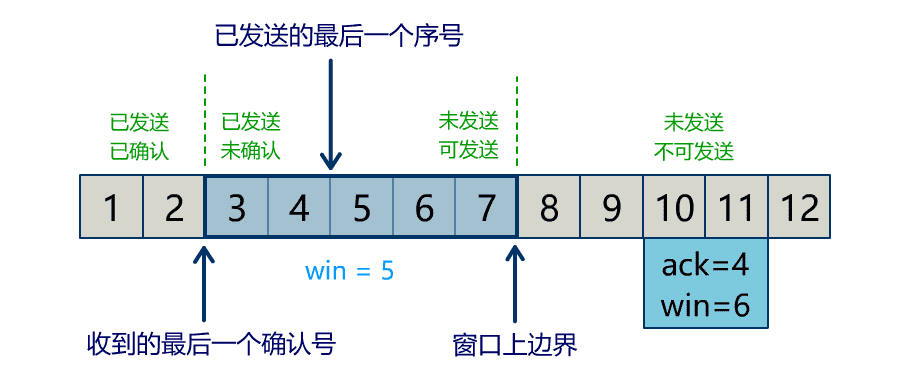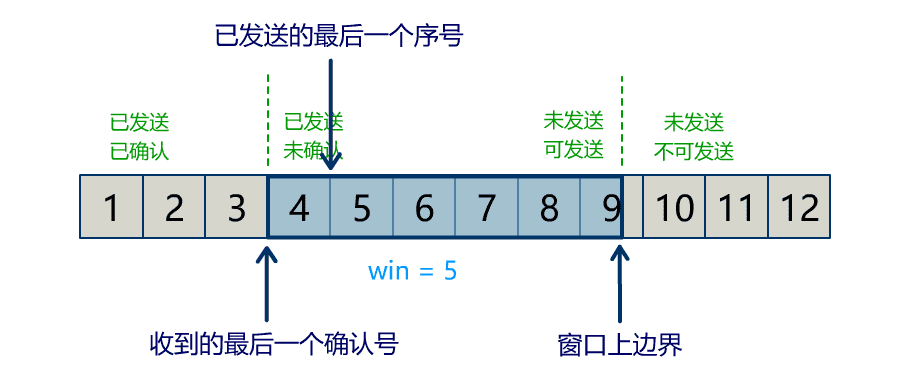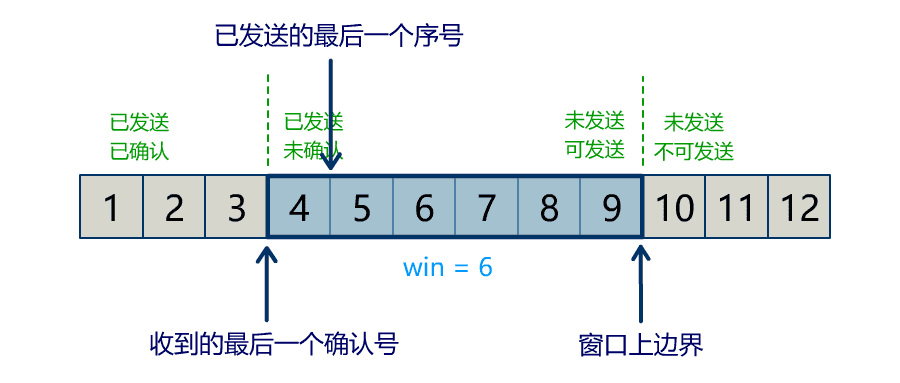
Buffer 中有三个属性最为重要:position, limit, capacity,首先给个结论:0 <= position <= limit <= capacity。
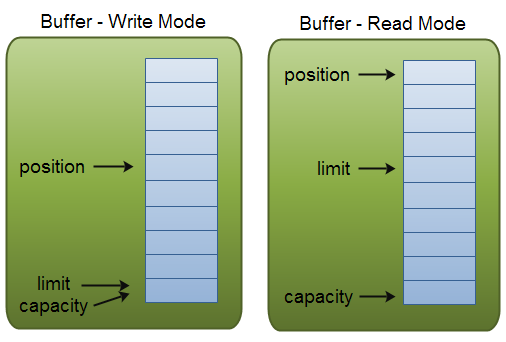
capacity
Buffer 的 capacity 在初始化时就被确定了,并且无法修改。你只能往里写 capacity 个 byte, long, char 等类型。一旦 Buffer 满了,需要将其清空(通过读数据或者清除数据)才能继续往里写数据。
position
当写模式时,position 表示当前写入的位置。初始的 position 值为 0,最大值为 。当一个数据写到 Buffer 后,position 会向前移动到下一个可插入数据的 Buffer 单元。
当读模式时,position 表示当前读取的位置。当将 Buffer 从写模式切换到读模式,position 会被重置为0。当从 Buffer 的 position 处读取数据时,position 向前移动到下一个可读的位置。
limit
当写模式时,limit 表示你最多能往 Buffer 里写多少数据,等于 capacity。当切换到读模式时,limit 会被设置成写模式最后的 position 值,表示你最多能读到多少数据。
2.2 主要 API
allocate
每一个 Buffer 类都有一个 allocate() 方法,方法参数需要指定 capacity。
1 | ByteBuffer buf = ByteBuffer.allocate(48); // 分配48字节capacity的ByteBuffer |
read / write
读写数据,既可以操作 Channel 的 API,也可以操作 Buffer 的 API:
1 | int bytesRead = inChannel.read(buf); // 将数据从 Channel 写入到 Buffer 中 |
切换 Buffer 的读写模式时,需要调用 flip() 方法:会将 position 设回 0,并将 limit 设置成之前 position 的值。
1 | int bytesWritten = inChannel.write(buf); // 从 Buffer 读取数据到 Channel 中 |
其中 Buffer 的 get() 和 put() 方法有许多重载方法,可以读取/写入特定数据类型的数据,或是操作指定 position 的数据,具体见 JavaDoc。
rewind
该方法会将 position 设回 0,limit 保持不变:实现 Buffer 中数据的重新读取。
clear / compact
当读完 Buffer 中的数据后,需要让 Buffer 准备好再次被写入。可以通过 clear() 或 compact() 方法来完成。
如果调用的是 clear() 方法:position 将被设回 0,limit被设置成 capacity 的值。
如果调用的是 compact() 方法:将所有未读的数据拷贝到 Buffer 起始处。然后将 position 设到最后一个未读元素正后面。limit属性设置成capacity。
由此可见:
- 对于 clear() 方法虽然数据没有被清理,但是由于 position 被重置,后续进行写数据时数据会被覆盖。
- 对于 compact() 方法,会根据 position 和 limit 判断出哪些数据未读,将这些未读的数据移动到 Buffer 开头,然后将 position 置在最后一个未读元素正后面,保证未读数据不会被覆盖。
mark / reset
通过调用 mark() 方法,可以标记 Buffer 中的一个特定 position,之后可以通过调用 reset() 方法恢复到这个position。例如:
1 | buffer.mark(); |
equals / compareTo
满足以下条件时,表示两个 buffer 相等:
- 有相同的类型(byte、char、int等)
- Buffer 中未消费数据的个数相等,每一个元素相等
注:其中未消费数据指 position 到 limit 之间的元素
满足以下条件时,则认为一个 Buffer 小于另一个 Buffer:
- 第一个不相等的元素小于另一个Buffer中对应的元素
- 所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)。
2.3 Scatter / Gather
使用 Channel 进行读操作时,可以将读取到的数据,写入到多个 Buffer 中,这个操作称之为 Scatter。
相对应的,使用 Channel 进行写操作时,可以从多个 Buffer 中,读取到要写入的数据,这个操作称之为 Gather。
一种使用场景时,当我们自定义消息协议时,比如消息头部分由 5 个字节组成,消息体由 10 个字节组成,为了区分消息体和消息头的内容:
- 一种实现是定义长度为 15 的 Buffer,然后再根据长度进行分割
- 一种实现是分配定义长度为 5 和 10 的 Buffer,借助 Scatter / Gather 特性,自动分散到这两个 Buffer 中
Scattering Reads
1 | ByteBuffer header = ByteBuffer.allocate(5); |
read() 方法按照 Buffer 在数组中的顺序将从 channel 中读取的数据写入到 buffer,当一个 buffer 被写满后,channel 紧接着向另一个 buffer 中写。
Scattering Reads 在移动下一个buffer前,必须填满当前的 buffer,这也意味着它不适用于动态(即长度不固定)消息。
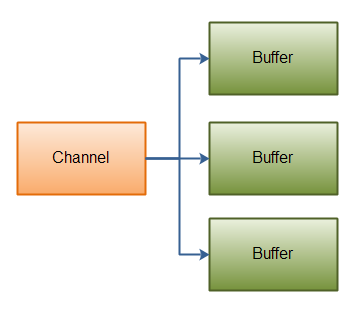
Gathering Writes
write() 方法会按照 Buffer 在数组中的顺序,将数据写入到 channel,注意只有 position 和 limit 之间的数据才会被写入。因此,如果一个buffer的容量为 128byte,但是仅仅包含 58byte 的数据,那么这 58byte 的数据将被写入到 channel 中。因此与 Scattering Reads 不同,Gathering Writes 能较好的处理动态消息。
1 | ByteBuffer header = ByteBuffer.allocate(5); |