一、摘要
LMAX 计划创建一个高性能的财务交易系统。作为我们工作的一部分,我们评估了多种方案去设计这个系统以求达到高性能目标,最后我们发现在传统的解决方案中遇到了基础上的瓶颈。
许多应用程序通过队列来在不同的处理阶段之间交换数据。我们的性能测试显示,如果按照传统的方式来使用队列,延时代价的量级和磁盘 IO 操作的延时量级是同一个量级——非常慢。如果在端到端的操作中采用多个队列,又会增加了几百个毫秒的额外开销【注:用于协调这些队列】。这里有很大的优化空间。
通过进一步研究和调研计算机科学,我们意识到传统方案(如:队列和处理节点)耦合了多个关注点,从而带来了多线程之间的资源争抢,表明可能有更好的方法。
结合现代 CPU 的工作原理,也就是我们常说的“机制共鸣”(mechanical sympathy)【注:意为参考现代 CPU 的设计思想,顺应底层设计思路,来做上层的应用设计,以便使用底层设计的优势,从而达到一个最佳的设计结果,得到一个‘共鸣’】,通过隔离关注,我们提出了一个数据结构和基于该数据结构的模式,这就是 Disruptor。
测试结果显示,对于一个三阶段的任务管道,Disruptor 的平均延时的数量级要小于基于传统队列的方法三个数量级。另外 Disruptor 的吞吐量是传统方法的 8 倍。
这些性能改进也意味着对于并发编程我们前进了一大步。对于高吞吐量和低延时的异步事件处理系统,这种新的模式是一个非常理想的基础组件。
在 LMAX 中,我们已经建立起一个订单匹配引擎,实时风险管理系统,以及一个高可用性的内存事务处理系统,这些系统在 Disruptor 下都取得了巨大的成功。这些系统中的每一个都建立了新的性能标准,据我们所知,这些标准是无与伦比的。
Disruptor 不只是专门为金融行业设计的,它具有相当的通用性,它能够解决并发编程中的一个复杂问题:如何最大化性能。这个系统的实现非常简单,尽管这里面的有些概念不是那么直观,但相比于其他机制,基于这种模式的系统往往更加简单。
相比于其他方法,Disruptor 的写竞争比较少,并发开销更低,而且更加缓存友好,吞吐量更高,延时抖动更低。对于一个普通时钟频率的处理器,Disruptor 每秒处理的消息量为 2500 万,延时低于 50 纳秒。 这个性能指标已经接近于现代处理器在多核之间交换数据的上限。
二、 概述
Disruptor 是 LMAX 开发的世界上最快的金融交易系统的产物。早期的设计思路主要借鉴 SEDA [1] 和 Actors[2] 的实现,希望使用 pipeline 来提升吞吐量。通过测试各种实现,我们发现管道(pipeline)在不同阶段(stage)之间,事件排队是性能的主要杀手。我们发现队列带入了剧烈的延时抖动。我们为了达到更好的性能于是花了很多精力来开发一个新的队列实现。然而最终发现队列有其局限性——耦合了生产者、消费者、数据存储等多个关注点。Disruptor 的实现很好地隔离上述关注点。
三、并发的复杂性
本文遵循计算机科学的通用定义:并发不仅是说有两个或者多个任务同时执行,还意味着对资源的竞争访问。这些竞争的资源可能是数据库、文件、Socket 或者内存中的某个地址。
代码的并发执行主要有两个方面:互斥和变化的可见性。 互斥主要用来管理对某些资源的竞争更新。变化的可见性主要是用来控制什么时候这些变化对其他线程可见。如果你能够在应用层面上限制并发更新那么你就有可能避免互斥。比如,如果你的算法能够确保任何资源只会被一个线程更新,那么互斥就是不必要的。读或者写要求所有的变化对其他线程可见,但实际上只有竞争写操作才真正需要互斥。
并发环境中最耗费时间的操作其实就是并发写。多线程对同一个资源的写需要复杂昂贵的协调,通常会通过某种锁来实现资源协调。
3.1 锁的代价
锁提供了互斥,并确保以有序的方式发生更改。锁其实是很昂贵的,因为它们在竞争的时候需要进行仲裁。这个仲裁会涉及到操作系统的上下文切换,操作系统会挂起所有在等待这把锁的线程,直到锁持有者释放该锁。上下文切换期间,执行线程会丧失对操作系统的控制,导致执行线程的执行上下文丢失之前缓存的数据和指令集,这会给现代处理器带来严重的性能损耗。 当然效率更高的用户态锁是另一种选择,但用户锁只有在没有竞争的时候才真正会带来益处【注:因为用户态的锁往往是通过自旋锁来实现(或者带休眠的自旋锁),而自旋在竞争激烈的时候开销是很大的(一直在消耗CPU资源)】。
为了探究影响到底有多大,我们写了一个程序,这个程序很简单,就是调用一个循环 5 亿次递增操作的函数。这个 Java 函数在单线程,2.4G Intel Westmere EP 的 CPU 上只需要 300ms。
一旦引入锁来提供互斥,即使锁还没有发生竞争,程序的执行时间也会发生显著的增加。当两个或多个线程开始竞争时,成本将再次增加几个数量级。实验结果如下:
| Method | Time (ms) |
|---|---|
| Single thread | 300 |
| Single thread with lock | 10,000 |
| Two threads with lock | 224,000 |
| Single thread with CAS | 5,700 |
| Two threads with CAS | 30,000 |
| Single thread with volatile write | 4,700 |
3.2 CAS 的代价
除了锁之外,另外一种方法是 CAS。CAS 依赖于处理器的支持,当然大部分现代处理器都支持的。CAS 相对于锁是非常高效的,因为它不需要涉及内核上下文切换进行仲裁。但 CAS 并不是免费的,处理器需要对指令 pipeline 加锁以确保原子性,并且会用到内存栅栏(Memory Barrier)以确保对其他线程的可见性。 JAVA中的 java.util.concurrent.Automaic 类用到了 CAS 操作。
如果程序的关键部分比计数器的简单递增更为复杂,则可能需要使用多个 CAS 操作来协调竞争的复杂状态机。用锁进行并发编程就已经很头疼了,使用 CAS 操作和内存屏障开发无锁算法要复杂很多倍,且很难保证正确性。
最理想的算法就是只有一个线程来负责对单个资源的所有写,而其它所有的线程都是读结果。要在多处理器环境中读取结果,需要有内存栅栏,以使更改对其他处理器上运行的线程可见。
3.3 内存栅栏 Memory Barriers
现代处理器为了获得更高的性能会做指令重排,在内存和执行单元中,指令执行、数据的加载和存储都会被进行指令重排。处理器只需要确保程序逻辑能得到相同的结果,它不会关心指令的执行顺序。对于单线程程序,指令重排不会有问题,但对于共享状态的多线程程序而言,内存有序变化就变得非常重要。处理器用内存栅栏来标识对内存更新顺序敏感的代码片段,它们确保确保指令的硬件执行顺序和内存变化在线程间的可见性。编译器可以在代码的合适位置放置额外的软件栅栏(software barriers)来确保被编译代码的执行顺序,这些软件内存栅栏是附加在处理器自身的硬件栅栏之上的。
现代 CPU 相比内存系统来讲速度是非常快的。为了桥接( bridge )其各个 CPU,现代处理器使用了复杂的缓存系统,这些缓存实际上是一些高效的独立的硬件哈希表。不同 CPU 之间的缓存是通过消息传输协议来保证一致性。另外,处理器还会使用“存储缓冲区”缓解对缓存的写压力,使用“失效队列”确保在写操作发生时,缓存一致性协议能快速知道失效消息【注:实现细节不是很了解】。
对于此种实现方式,最近写入的数据可能处于任何存储中:在寄存器里、在存储缓冲区中、在各级缓存中、在主存中。如果多个线程要共享这个值,那么这个值必须要按照一定的顺序对其它线程可见,这种可见性是通过交换缓存一致性消息来协调完成的。内存栅栏可以控制这些消息的适时产生。
读内存栅栏(a read barrier)确保 CPU 上的加载指令有序,当缓存发生变化时,读内存栅栏会在失效队列上标记一个点。读内存栅栏标记点之前的写操作可以通过内存栅栏提供一致性视图(view)【注:读内存栅栏会在“失效队列”中标记一个节点,这个节点意味着read barrier 之前读取的所有数据都已不可靠(这也就告诉我们可能有变化发生),之后的所有读操作都需要重新从内存中加载,因此之后的操作从而能够看到数据的最新变化,barrier 之前的所有线程的写指令和 barrier 之后的读指令就有了一个先后顺序。Read memory barrier 使得排在 read memory barrier 之前的写操作成为一个整体,在这个整体内部写操作的顺序是不确定的,但这个整体形成了一个完整的视图,整个整体的结果对后面的操作是可见】。
写内存栅栏(a write barrier)用来确保 CPU 的存储指令有序,写内存栅栏会在存储缓冲区(store buffer)中标记一个点,这个标记点之前的数据变化(write 操作)会通过缓存刷新(flush)到主存。写内存栅栏标记点之前发生的存储操作可以通过写内存栅栏提供有序性视图。
一个完整的内存屏障(a full barrier)命令的加载/存储操作只能在执行它的 CPU 上执行【注:原文不太会翻译。 A full memory barrier orders both loads and stores but only on the CPU that executes it. 】。
【注:综上所述,实际上 read barrier 意味着 read 操作不能穿越这个 read barrier,write barrier 意味着 write 操作不能穿越这个 write barrier。执行 read barrier 的 CPU 是多线程中的消费者的角色,它通过 read barrier 能够尽快看到生产者线程的执行结果。而执行 write barrier 的 CPU 往往充当生产者的角色,它通过 write barrier 把自己执行的结果尽可能快得让其它线程看见。】
一些 CPU 在上述三个基础栅栏基础上引入了很多变化,但是通过这三个基础栅栏足以理解内存栅栏期望解决问题的复杂性。在 Java 内存模型中,对 volatile 域的读取和写入实际上就是对应的 read barrier 和 write barrier。Java 内存模型[3]规范对此有明确的定义。
3.4 缓存行 Cache Lines
在现代处理器中使用缓存的方式对于性能的影响非常重要。这样处理器在处理缓存中保存的数据和指令时非常高效,但是,当发生高速缓存未命中时,就会导致效率极低。
硬件并不是以字节或字为单位操作缓存,为了效率考虑,缓存通常以缓存行(cache line)的形式进行组织( organised ),缓存行通常有 32-256 字节,最常见的是 64 字节。缓存行也是缓存一致性协议操作的最小粒度。这就意味着:如果两个变量不幸在同一个缓存行里,而且它们分别由不同的线程写入,那么这两个变量的写入会发生竞争,就好像多线程在竞争写入同一个变量一样。这种现象被称之为“伪共享”(false sharing)。出于高性能的考虑,需要确保独立但被并发写入的变量之间不会共享同一个缓存行,以求将资源竞争降到最低。
可预测式的 CPU 访问主存【注:这里的 memory 译为主存,以便和缓存(cache)区分开来】时,通常会预测接下来将被访问到的主存内容并在后台将它加载到缓存中,从而将主存访问产生的时延降至最低。主存预读取发生的前提是:处理器能够检测到主存访问的模式/规律,主存预读取就像是以一个可预测的‘步幅’(stride)在主存中行走。比如说:当对一个数组的内容进行迭代时,‘步幅’是可预测的,这样主存中的内容就能预读取到缓存行中,最大化访问主存的效率。在处理器能感知到的任何方向中,‘步幅’通常要小于 2048 字节。然而,像链表(linked lists)和树(trees)这样的数据结构在主存中拥有分布广泛的节点,从而没有可预测的访问‘步幅’【注:由于链表或者树各个节点之间分布并不是顺序的,相邻节点的存储地址相隔很远,所以处理器找不到对应的读取规律,无法进行预读取。】,由于主存中缺乏一致的模式限制了系统预取缓存行的能力,导致主存访问的效率可能低了 2 个数量级。
3.5 队列的问题
典型的队列要么使用链表要么使用数组作为底层的数据存储。如果一个内存队列是无界的,很大情况,它会变得不可控直到消耗大量内存导致严重错误。这通常发生在生产者处理能力好于消费者的场景下。无界队列在生产者能保证不超过消费者消费能力的情况下非常有用,但是仍然有担保失效的风险。为了避免灾难发生,队列通常是有界的,为了确保队列有界就要求它是数组形式或者他的大小是被跟踪的。
常见的队列形式下,在队列的头(消费者频繁使用)、尾(生产者频繁使用)以及长度(生产者和消费者都需要频繁更改)会产生资源竞争。当队列在使用时,在大多数情况下队列要么是几乎是满的,要么几乎是空的,这是由于生产者和消费者不同的工作节奏造成。很少能取得平衡以使消费者和生产者的工作节奏完美匹配。几乎为满或者几乎为空的队列会导致严重的资源竞争和为了维护缓存一致性而带来的高昂消耗。【注:以一个几乎为空队列为例,大量的消费者被阻塞,在可消费的 entity 上产生资源竞争,同时缓存对应的内容迅速变化,导致各个 CPU 之间维护缓存一致性的成本急剧上升】。即便为队列的头和尾使用不同的同步对象(比如锁或者 CAS 变量)也同样存在问题,因为这些不同的同步对象对应的主存内容通常位于同一个缓存行中,对这些同步对象的频繁操作也会带来资源竞争【注:这里不太确定位于同一个缓存行的是同步对象还是队列的头和尾对象】。
生产者声明队列的头,消费者声明队列的尾,以及两者之间的节点存储的问题使得并发实现的设计非常复杂,除了在队列上使用单个大粒度锁(large-grain)之外,很难进行管理。在 put 和 take 上添加单个大粒度锁实现起来非常简单,但是却成为吞吐量的瓶颈。如果想要很好得解决队列场景下的并发问题,那么队列的实现就必然很复杂,当然如果是单生产者-单消费者的场景除外。
Java 里使用队列还有一个更大的问题:队列会成为很大的垃圾回收源。首先,队列中的对象需要被分配和替换,再者,当链表重新寻址,对象需要重新分配。当队列中的对象不再被引用时,所有这些对象都需要被回收。
3.6 管道和图 Pipelines and Graphs
很多问题场景下,需要将多个处理阶段绑定在一起组成管道,这个管道通常以并行地方式组织成图的拓扑结构。各个阶段之间通常使用队列来连接,同时每个阶段会有自己的处理线程。
这种处理方式并不便宜( cheap )——每个阶段都会有入队和出队的开销,当路径必须分叉(fork)时,有多少个目标消费者,就会增加多少倍的成本【注:到每个消费者都会有入队操作】;同时,分叉之后还需要合并,这时候会因为不可避免的资源竞争产生额外的成本。
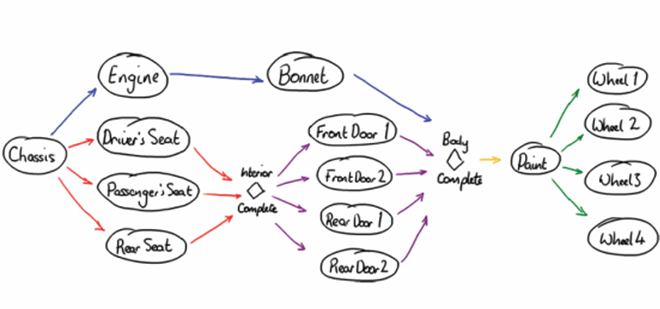
上图举了一个管道和图的例子。内容是如何组装一台汽车。 要组装一台汽车,我们第一阶段要有底盘(chassis),接着装引擎(Engine),装驾驶员座椅(Driver’s Seat),装乘客座椅( Passenger’s Seat),装后座座椅(Rear Seat)等等,最后是装四个轮子(Wheel)。这里每个圆圈都代表一个 Stage。箭头代表依赖关系,只有四个门和引擎盖都装好了(Bonnet)才能进行喷漆(Paint)工作。每个箭头都意味着一个队列,箭头两端代表着生产者和消费者。每个消费者和消费者都意味着一个线程。比如对于 paint 而言,它拥有五个消费者线程来处理队列。
四、LMAX Disruptor 的设计
为了解决上面提出的问题,该设计严格地实现了关注分离(separation of the concerns)。该设计确保任何数据只被一个线程进行写访问,从而避免写冲突。这个设计就是 Disruptor,之所以叫这个名字是因为它和 Java7 中出现的 “Phasers”[4] 有很多相似之处。
Disruptor 的设计初衷就是为了解决上面提到的问题【注:锁代价过大、CAS代价过大、缓存行导致的伪共享、队列存在的问题】,以求最优化内存分配,使用缓存友好的方式来最佳使用现代硬件资源。
Disruptor 的核心机制在于:以 RingBuffer 的形式预分配有界的数据结构,单个或者多个生产者可以向 RingBuffer 中写入数据,单个或者多个消费者可以从 RingBuffer 读取数据。
4.1 内存分配 Memory Allocation
Ringbuffer 的内存是在启动时预先分配的。Ringbuffer 要么是一个引用数组,每个元素是指向对象的引用【注:针对C#、 java这样的语言】,要么是一个结构数组,每个元素(entry)代表的就是对象实体【注:针对C、C++这样的语言】。由于 Java 语言的限制,Java 实现的 Ringbuffer 实际上只能是一个引用数组。每个元素只能是一个数据的容器,而不是数据本身。这种预先分配的策略就能够避免 Java 内存回收引起的一些性能问题,因为这些元素对象(enries)在能够在 Disruptor 实例中的整个生命周期存活和被复用【注:这些元素(enties)一直被 RingBuffer 对象持有,而 RingBuffer 实例对象又被 Disruptor 持有,故只要 Disruptor 存在,则这些 enties 便不会被 GC】。由于这些对象是在开始阶段同时分配的,很大程度上被连续分布在主存中,即使不连续它们在内存中的间隔也有可能是固定的,从而支持缓存步幅,非常有利于缓存的数据预取。John Rose 提出了一个草案希望未来 JAVA 能够支持所谓的 “value type”[5],就像C语言那样,如果这样的话,Disruptor 就能够确保对象在内存中一定是连续的,而不仅仅只是有很大可能性了。
对于 Java 这样的运行环境来讲,垃圾回收对于低延时系统是一个严重的挑战。内存越大,垃圾回收造成的性能压力也就越大。垃圾回收喜欢的对象要么寿命非常短,要么对象干脆是永生的。Ringbuffer 的预先分配使得我们的对象变成了永生的对象,大大减轻垃圾回收的压力。
在高负载的情况下,基于队列的系统可以 back up,这会降低处理效率,进而导致被分配的对象比原本存活得更长,在使用分代垃圾收集器的 JVM 中,这些对象将会从年轻代进入老年代。这就意味着:
-
这些对象被不断地在各代之间【注:年轻代 eden gen 和 suviving erea,以及 young gen 和 old gen 之间】进行拷贝,造成延时波动;
-
进入老年代的对象回收成本会更高,GC 带来的内存碎片也会更多,引起 ‘stop the world’ 的概率会更大;越多的临时对象进入到老年代,也更可能带来性能上的损耗。
【注:如果对象是永生的。那么第一点的代价无法避免,但第二点的代价就会大大降低,因为这些对象一直会存在,那么老年代触发 major collection 时它扫描一下所有对象,发现这些对象都无法释放,什么都不用干,那就直接收工。由于对象不会被释放,那也就不会有碎片,那么 stop the world 的概率也就大大降低了。永生对象在第二点中所做的只不过是进行一次扫描,这个代价非常小。】
下面通过分析 ArrayBlockingQueue 和 RingBuffer 来加深 Disruptor 内存预分配所带来的好处。
在 ArrayBlockingQueue 中,数组 Object[] items 负责存储队列中的所有元素,如下图所示,当消费者消费完 items[0] 元素,紧接着生产者向 items[0] 放入新的元素 entity1,这时候 items[0] 存储的是对象 entity1 的引用,items[0] 到 entity0 对象的引用被切断,entity0 等待被 GC。生产者不断地向 items[0] 中写入消息,则老的 entity 将不断地需要被 GC,一旦队列阻塞,items 可能熬过多次minor GC,幸存下来,并进入到老年代,带来更严重的性能隐患。

再来看看 RingBuffer 预分配内存方式的精妙之处。RingBuffer 同样使用数组 Object[] entries 作为存储元素。如下图所示,初始化RingBuffer 时,会将所有的 entries 的每个元素指定为特定的 Event,这时候 event 中的 detail 属性是 null;后面生产者向 RingBuffer中写入消息时,RingBuffer 不是直接将 enties[7] 指向其他的 event 对象,而是先获取 event 对象,然后更改 event 对象的 detail 属性;消费者在消费时,也是从 RingBuffer 中读取出 event,然后取出其 detail 属性。可以看出,生产/消费过程中,RingBuffer 的 entities[7] 元素并未发生任何变化,未产生临时对象,entities 及其元素对象一直存活,直到 RingBuffer 消亡。故而可以最小化 GC 的频率,提升性能。

4.2 隔离关注 Teasing Apart the Concerns
我们认为以下问题在所有队列实现中都是混杂在一起的,在某种程度上,这种独特行为的集合倾向于定义队列实现的接口:
- 队列元素的存储
- 队列协调生产者声明下一个需要交换的队列元素的序号
- 队列协调并告知消费者等待的元素已经就绪
在使用带有垃圾回收特性语言来设计金融用的交换机(exchange)时,过多的内存分配会带来麻烦,所以,我们基于链表的队列不是一个好的解决方案。如果用于存储各个阶段交换数据的节点(entries)可以被预先分配内存,那么垃圾回收可以被最小化;更进一步地,如果节点被统一分配为相同大小的块,那么在遍历节点时,将会以一种缓存友好的方式进行,效率会更高。预分配内存的数组满足上述的要求,在创建 RingBuffer 时,DIsruptor 使用抽象工厂模式预分配了所有节点,当一个节点被声明时,生产者只需要将它的数据拷贝到这个预分配的数据空间中即可。
对于现代处理器而言,取余操作是一种比较昂贵的操作。但在 RingBuffer 中取余是一个使用频率很高的操作,因为需要计算某一个序号在 RingBuffer 中的位置需要用到取余。一个替代的方法是将 RingBuffer 的长度设置为2的幂次方,这样通过简单的位操作就可以获取余数。
我们前面提到,有界队列会在队列头和队列尾形成激烈的竞争。但是 RingBuffer 使用的数据结构则没有这种竞争和并发,因为RingBuffer 将这些竞争的焦点(concerns)转移到了生产者/消费者栅栏(barriers)上去,接下来我们将详细阐述这一逻辑。
Disruptor 的典型应用场景通常只有一个生产者,典型的生产者是文件读取或者网络侦听。如果只有一个生产者,那么队列元素分配或者序号分配不会存在竞争。
但在一些特别的场景,Disruptor 会有多个生产者,这种情况下生产者们可能会彼此竞争来获取 RingBuffer 中下一个可用的位置,这里的竞争问题可以通过 CAS 操作来处理。
当生产者将相关的数据拷贝到 RingBuffer 的位置(entry)中后,生产者提交这个序号,告知消费者这个位置的数据可以消费了。这里可以不使用 CAS 操作,而是用简单地自旋直到等待的其他生产者都到达了这个序号便可提交。【注:RingBuffer 通过一个游标(cursor)来告知消费者当前那些位置可以被消费,多个生产者时,需要确保游标之前的 seq 都已经提交,故而这里需要协调各个生产者】。为了避免覆盖情况发生【注:覆盖是指生产者速度快于消费者速度,导致生产者写入消费者还未来得及消费的位置】,生产者在写入前会检查所有消费者最小的 seq,确保写入的 seq不 会大于这个最小的消费者 seq。
消费者在读取元素之前需要等待一个序号,该序号指示了有效的可以读取的元素。怎么样等待这个序号,有很多种策略。如果 CPU资源比较宝贵,那么消费者可以等待某一个锁的条件变量,由生产者来唤醒消费者。这种方式明显会带来竞争,只适用于 CPU 资源的稀缺性比系统的延时/吞吐量重要的场景。另外一种策略是所有消费者线程循环检查游标(cursor),该游标表示 RingBuffer 中当前有效的可供读取的元素的位置,这种策略使用更多消耗 CPU 资源来换取低时延。这种方法由于没有用锁和条件变量,因此打破了生产者和消费者之间的竞争依赖关系。如果你想支持多生产者-多消费者的场景,你就不得不采用很多 CAS 操作,这些 CAS 操作作用在头、尾、队列长度等等,这就带来了复杂性。但 Disruptor 避免了这种复杂的 CAS 竞争。
4.3 序列化 Sequencing
顺序化是 Disruptor 管理并发的核心概念。每个生产者和消费者都维护自己的序号,这个序号用来和 RingBuffer 交互。当一个生产者希望在 RingBuffer 中添加一个元素时,它首先要做的是声明一个序号【注:这个序号被称之为生产者的声明序号,该序号用来指示下一个空闲的插槽(slot )的位置,一旦序号被声明,那么该序号就不会被其它生产者重复操作,生产者就可以操作该声明序号的 slot 数据】。单生产者的场景下,这个声明序号可以是一个简单的整数;多生产者的场景,这个序号必须是一个支持 CAS 的原子变量。当一个生产者序号被声明,这个序号对应的位置就可以被声明该序号的生产者写入了;当生产者完成更新元素后,它就通过更新一个单独的序号来提交变化,这个单独的序号是一个游标(cursor),用来指示消费者可以消费的最新的元素。生产者可以通过一种自旋的方式来读取和更新 RingBuffer 的游标,这里只需要使用内存栅栏而不需要使用 CAS 操作,如下:
1 | long expectedSequence = claimedSequence – 1; |
消费者等待指定的消费者序号变得可用,它通过内存栅栏(memory barrier)来读取游标(cursor),一旦游标的值被更新,内存栅栏会确保 RingBuffer 中的这一变化会被所有在游标上等待的消费者可见。【注:通过这种机制,消费者能够及时知道生产者提交了新的消息,并尝试进行消费】。
每个消费者都各自维护一个序号来表示自己最新消费的位置序号。生产者通过跟踪这些序号来确保不会覆盖消费者还未来得及消费的位置,同时这些序号也可以用于协调消费者之间的执行顺序【注:Disruptor 中的多消费者实际上是指对于同一个 event,有多个处理阶段,每个阶段被认为是一个独立的消费者,各个阶段的执行通常是有顺序要求的】。
单生产者场景下,不管消费者有多么复杂的依赖,Disruptor 都无需使用锁和 CAS 操作,它通过多个序号(Sequences)上的内存栅栏就可以协调整个并发场景。【注:Disruptor 中有两类 Sequence——生产者序号(又叫 cursor)和消费者序号,通过在这两个序号上建立内存栅栏,达到协调并发的目的】。
4.4 批量效应 Batching Effect
当消费者等待 RingBuffer 中可用的前进游标序号时,如果消费者发现 RingBuffer 游标自上次检查以来已经前进了多个序号,消费者可以直接处理所有可用的多个序号,而不用引入并发机制, 这样滞后的消费者能够迅速跟上生产者的步伐,从而平衡系统,这一特性是队列(queues)不具有的。这种类型的批处理增加了吞吐量,同时减少和平滑了延迟。 根据我们的观察结果,无论负载如何,时延都会维持在一个常数时间值上,直到存储子系统饱和,曲线是线性的,遵循 Little’s Law[6] 定律。 这与在负载增加时观察队列所得到时延 “J” 曲线效应非常不同。
4.5 依赖图 Dependency Graphs
队列从本质上来讲表示一个简单的消费者和生产者之间的只具有一步的管道(pipeline)。如果消费者形成了一个链条,或者一个图状的依赖关系,那么图中的每个阶段之间都会需要一个队列。大量的队列就带来了开销。在设计 LMAX 金融交易系统的过程中,我们发现基于队列的设计方法会导致大量的队列开销,而这些为数众多的队列所带来的开销耗费了事务处理的大部分时间。
在 Disruptor 设计模式中,生产者和消费者的竞争被很好得隔离开了,因此通过使用一个简单的 RingBuffer 也可以在消费者之间构造复杂的依赖关系。这样降低了执行时延,从而提高了吞吐量。
一个 RingBuffer 可以用来处理一个具有复杂的依赖关系图的流程。设计 RingBuffer 的时候需要特别注意,需要避免消费者之间错误的共享缓存行。
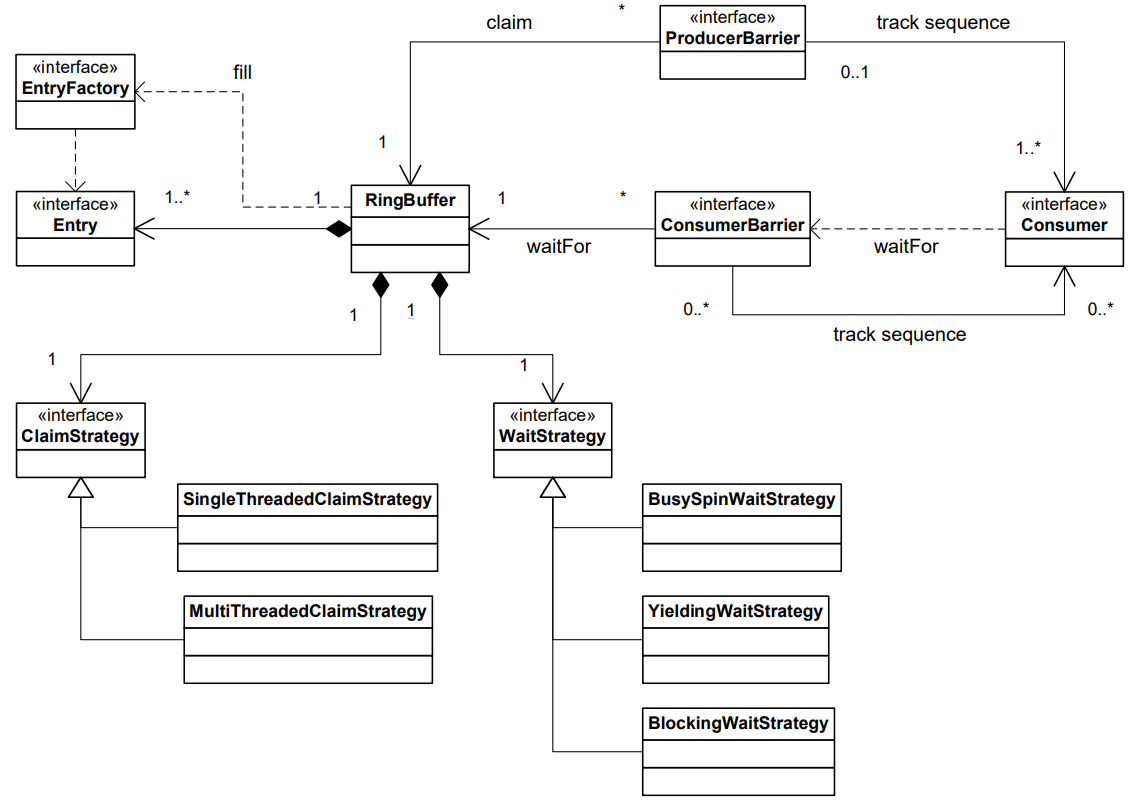
4.6 Disruptor 类图
下图是 Disruptor 框架的核心类图。这个图里遗漏了一些简化编程模型的类。一旦业务流程的依赖关系图构建完毕,那么编程模型就变简单了。生产者通过 ProducerBarrier 来顺序申请 entry,同时将数据变化写入 entry 中,然后再通过 ProducerBarrier 来提交数据变化并使得这些变化对消费者可见。作为一个消费者,它所需要做的只不过是提供一个 BatchHandler 实现,当一个新的 entry 可见时,这个回调会被触发。这使得 Disruptor 编程模型是一个基于事件的模型,和 Actor 模型类似。
为了更灵活的设计,队列通常将关注点组合起来考虑。RingBuffer 是 Disruptor 模式的核心,它为数据交换提供了存储,同时又避免了竞争。通过 RingBuffer,生产者和消费者之间的并发问题被隔离开了。ProducerBarrier 就是用来管理RingBuffer中的位置槽(slot)声明,同时跟踪相关的消费者从而避免冲突覆盖。而 ConsumerBarrier 在有新的元素有效时会负责通知消费者。通过这些barrier,消费者之间就构造成了一个依赖关系图,这个依赖关系关系图实际上代表了流程处理过程中的各个阶段。
【注:本篇文章是基于 Disruptor1.0 的,因此下面的类图也是 1.0 版本的,现在已经更新到 3.4 版本,类图已经有了很大的改变。】
4.7 代码示例
下面的代码示例是一个单生产者和单消费者的场景,它通过 BatchHandler 来实现消费者。消费者运行在一个单独的线程上,当元素可用时,它被用来接收元素。
1 | // Callback handler which can be implemented by consumers |
五、吞吐量性能测试 Throughput Performance Testing
作为参考,我们选择了 Doug Lea 的 java.util.concurrent.ArrayBlockingQueue[7],根据我们的测试,它在所有有界队列中具有最高的性能。测试是按照阻塞的方式进行的以匹配 Disruptor。以下详细描述的测试用例可在 Disruptor 开源项目中找到。注意:运行测试需要一个能够并行执行至少 4 个线程的系统。
Unicast: 1P – 1C:
Three Step Pipeline: 1P – 3C:

Sequencer: 3P – 1C:
Multicast: 1P – 3C:
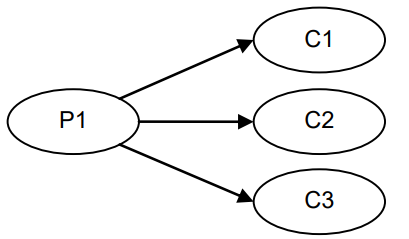
Diamond: 1P – 3C:
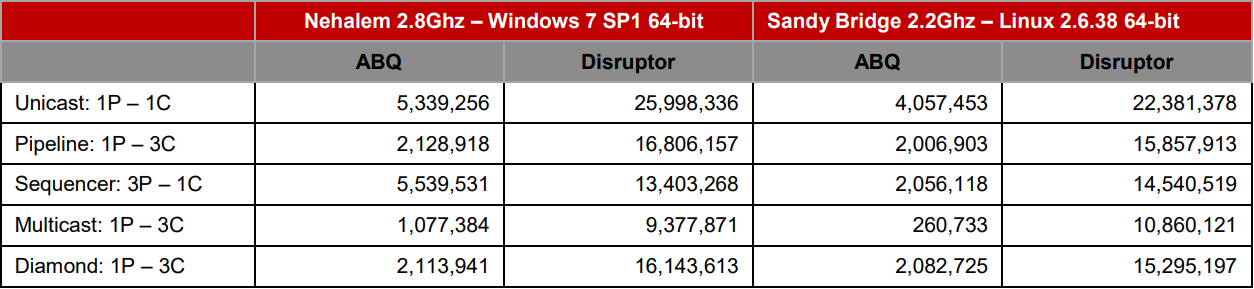
上述配置中,ArrayBlockingQueue 被用于每一个数据流箭头的位置,相当于 Disruptor 中的栅栏所处的位置。下表展示了总共处理 5 亿条消息时每秒吞吐量的性能测试结果,测试环境为:没有 HT 的 1.6.0_25 64-bit Sun JVM, Windows 7, Intel Core i7 860 @ 2.8 GHz ,以及 Intel Core i7-2720QM, Ubuntu 11.04。 我们取了最好的前三条结果,这个结果使用于任何 JVM 运行环境,表中显示的结果并不是我们发现最好的结果。
六、 延迟性能测试 Latency Performance Testing
为了测量延时,我们采用 3 个阶段的 pipeline 作为测试场景,为了能够测出系统的最佳状态,我们让吞吐量压力维持在一个合适的水准,这个压力不至于耗尽队列资源。这个压力是通过每插入一个事件就等待 1ms 的方式来实现的,然后一直这样重复 5000 万次。为了精确测量延时,我们需要精确考量 CPU 的时间戳计数器(TSC)。我们采用了那些 TSC 恒定的 CPU 来作为测试机器,因为老的 CPU 为了节省功耗,往往会自动调节 TSC。Intel Nehalem 之后的 CPU 都支持恒定的TSC。可以使用运行于 Ubuntu 11.04 上的 Oracle 最新版本的 JVM 进行测试,本测试未做 CPU 绑定。
我们依然采用 ArrayBlockingQueue 用来对比,而没有选取 ConcurrentLinkedQueue[8],原因在于我们期望使用一个有界队列来确保生产者不会超过消费者,从而避免产生过载,对测试产生影响【注:ConcurrentLinkedQueue 虽然性能更好,但是由于 Disruptor 模式的 ringbuffer 是一个长度固定的队列系统,而 ConcurrentLinkedQueue 是一个长度没有限制的队列,两者对于长度无限制的队列,生产者如果效率过高,且又无法阻塞,这样会抢占消费者的CPU资源,从而影响最后的测试结果】。
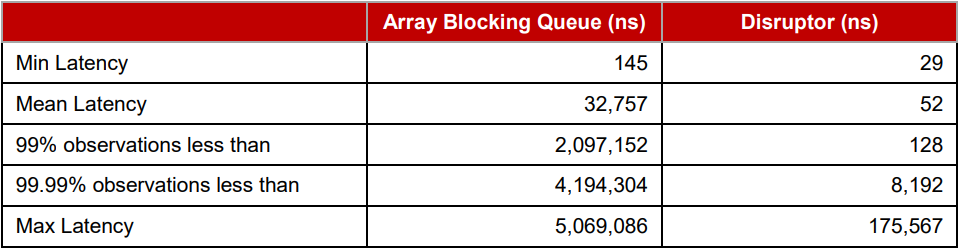
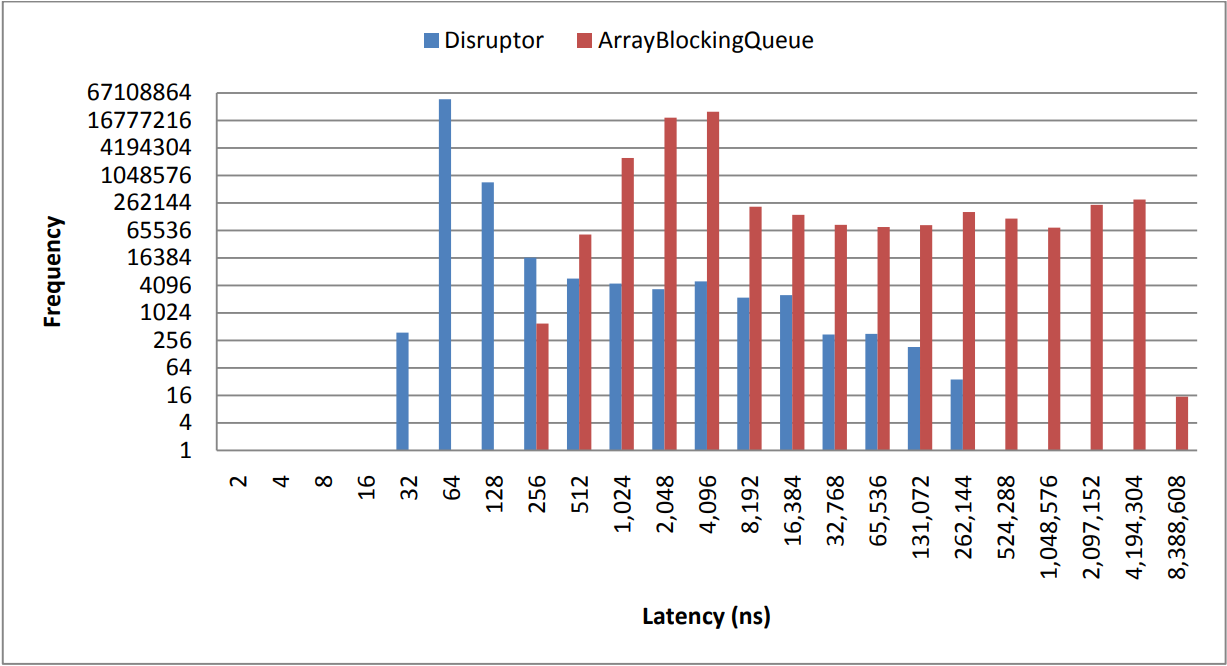
Disruptor 每一轮【注:一次完整的流水线】的平均延时为 52ns,相比之下 ArrayBlockQueue 每一轮的平均延时为 32757ns。跟踪显示 ArrayBlockQueue 性能损失主要是由条件变量的加锁/通知引起的。下表中测试结果是在配置为 2.2Ghz Core i7-2720QM 的 Ubuntu 11.04 操作系统上运行版本为 Java 1.6.0_25 64-bit 的 JVM 虚拟机得到的。
七、结论
Disruptor 在“提高吞吐量-降低时延”的领域里迈出了重要一步,这在许多应用中都是非常重要的考虑。我们的测试显示,与其它线程间交换数据的方法相比,Disruptor 的性能是最好的。我们相信 Disruptor 应该是所有数据交换方法中最好的。通过隔离关注,限制写竞争,最小化读竞争,代码的缓存友好化(cache-friendly),我们创造了一种在线程之间交换数据的高效的方法。【注:这里是指线程间交换数据,并未包含具体业务逻辑处理。】
批处理效应(Batch Effect)允许消费者能够一次性没有竞争的处理大量的元素,这为高性能系统提供了一个新的特性。对于大多数系统而言,随着吞吐量压力的增加,延时也会呈指数级增加,形成一个类似 J 的曲线。然而在 Disruptor 系统中,随着吞吐量压力的增加,延时依然会很平滑,直到内存被耗尽。
我们相信 Disruptor 建立了高性能计算的新基准,并且非常适合继续利用处理器和计算机设计的发展趋势。
Staged Event Driven Architecture – http://www.eecs.harvard.edu/~mdw/proj/seda/ ↩︎
Actor model – http://dspace.mit.edu/handle/1721.1/6952 ↩︎
Java Memory Model - http://www.ibm.com/developerworks/library/j-jtp02244/index.html ↩︎
Phasers - http://gee.cs.oswego.edu/dl/jsr166/dist/jsr166ydocs/jsr166y/Phaser.html ↩︎
Value Types - http://blogs.oracle.com/jrose/entry/tuples_in_the_vm ↩︎
Little’s Law - http://en.wikipedia.org/wiki/Little's_law ↩︎
ArrayBlockingQueue - http://download.oracle.com/javase/1.5.0/docs/api/java/util/concurrent/ArrayBlockingQueue.html ↩︎
ConcurrentLinkedQueue - http://download.oracle.com/javase/1.5.0/docs/api/java/util/concurrent/ConcurrentLinkedQueue.html ↩︎
 wechat
wechat- alipay





