Agrona 是 real-logic 开发的一个 Java 工具包,它提供了许多高性能的数据结构和工具方法,主要包括:
- Buffers - Thread safe direct and atomic buffers for working with on and off heap memory with memory ordering semantics.
- Lists - Array backed lists of int/long primitives to avoid boxing.
- Maps - Open addressing and linear probing with int/long primitive keys to object reference values.
- Maps - Open addressing and linear probing with int/long primitive keys to int/long values.
- Sets - Open addressing and linear probing for int/long primitives and object references.
- Cache - Set Associative with int/long primitive keys to object reference values.
- Clocks - Clock implementations to abstract system clocks, allow caching, and enable testing.
- Queues - Lock-less implementations for low-latency applications.
- Ring/Broadcast Buffers - implemented off-heap for IPC communication.
- Simple Agent framework for concurrent services.
- Signal handling to support “Ctrl + c” in a server application.
- Scalable Timer Wheel - For scheduling timers at a given deadline with O(1) register and cancel time.
- Code generation from annotated implementations specialised for primitive types.
- Off-heap counters implementation for application telemetry, position tracking, and coordination.
- Implementations of InputStream and OutputStream that can wrap direct buffers.
- DistinctErrorLog - A log of distinct errors to avoid filling disks with existing logging approaches.
- IdGenerator - Concurrent and distributed unique id generator employing a lock-less implementation of the Twitter Snowflake algorithm.
一、Agents
1.1 Duty Cycle
Duty Cycle 是一种编程模型,它是一个死循环程序,在循环中,去执行某个逻辑,并根据执行结果去决定是否要等待一会进行下次循环。例如:
1 | while (true) { |
1.2 Agent
在 Agrona 中,定义了 Agents:
1 | public interface Agent { |
doWork(),用于处理业务逻辑,它的返回值用于决定在 Agrona 中是否执行空闲策略:
- 当返回值大于 0 时,不触发空闲策略,Agrona 会立即执行下一次
doWork() - 当返回值小于等于 0 时,执行指定的空闲策略
除此之外,onStart() 和 onClose() 作为 Agent 启动和关闭时的回调钩子方法,roleName() 则申明了该 Agent 的名字。
1.3 Idle Strategies
Agrona 原生提供了一些空闲策略:
| Name | Implementation Details |
|---|---|
| SleepingIdleStrategy | 基于 parkNanos 实现线程暂停 |
| SleepingMillisIdleStrategy | 基于 thread.sleep 实现线程暂停,适合在低配置机器上进行本地开发或使用大量进程进行开发 |
| YieldingIdleStrategy | 使用 thread.yield 让出对线程的控制 |
| BackoffIdleStrategy | 一种激进的策略,先使用 spinning 再使用 yield(Thread.yield()),最后再根据配置的时间 parkNanos,这是 Aeron Cluster 默认的策略 |
| NoOpIdleStrategy | 最为激进的策略,不做任何处理 |
| BusySpinIdleStrategy | 对于 Java 9 及以上版本,将会使用 Thread.onSpinWait()。这向 CPU 提供了一个提示,即线程处于紧密循环中但忙于等待某事,然后 CPU 可能会在不涉及 OS 调度程序的情况下将额外资源分配给另一个线程。 |
如果需要自定义空闲策略,仅需要实现 IdleStrategy 接口即可:
1 | public interface IdleStrategy { |
上面的空闲策略并不一定保证线程安全,因此建议每个 Agent 使用独立的空闲策略
1.4 Agent Runner
Agent Runner 则负责将 Agent 和 Idle Strategies 组合并运行起来:
1 | final AgentRunner runner = new AgentRunner(idleStrategy, errorHandler, errorCounter, agent); |
上面是 AgentRunner 的构造方法,其中:
| 参数 | 含义 |
|---|---|
| idleStrategy | 空闲策略实例对象 |
| errorHandler | Agent 执行过程中出现异常时的回调处理器 |
| errorCounter | 记录 Agent 执行过程中出现异常的次数 |
| agent | Agent 实例对象 |
得到 AgentRunner 对象后,Agrona 提供以下三种方式来真正启动:
AgentRunner#startOnThread(AgentRunner),执行后会创建一个线程来运行AgentRunner#startOnThread(AgentRunner, ThreadFactory),会使用指定的 threadFactory 来创建独立线程- 将多个 Agent 组成一个
CompositeAgent,然后调用上面两种方式,这些 Agent 将会公用一个线程来运行
1.5 Agent Invoker
AgentRunner 的特点是当启动后,就会自动的执行,如果我们想手动控制 Agent 的运行,Agrona 提供了 AgentInvoker:
1 | final AgentInvoker agentInvoker = new AgentInvoker(errorHandle, errorCounter, agent); |
可以看到构造方法相较于 AgentRunner 去掉了空闲策略,因为是 Agent 是需要手动执行的,所以不需要这个参数。
二、Clocks
Agrone 提供了一套自己的 Clock API,首先它是基于 Epoch Time,也就是自 1970-1-1 00:00:00.000 到现在的时间差。顶层接口是 EpochClock,有种实现:SystemEpochClock 和 CachedEpochClock。
对于 SystemEpochClock,返回的是毫秒时间差,其实就是对 System.currentTimeMillis() 的封装,提供了一个静态实例用于操作:
1 | EpochClock clock = SystemEpochClock.INSTANCE; |
对于 CachedEpochClock,它其实就是一个缓存,主要有以下几个方法:
- update(long timeMs) 直接设置 timeMs 到缓存中
- advance(long timeMs) 在原有值基础上增加 timeMs 到缓存中
- time() 获取缓存值结果
1 | CachedEpochClock clock = new CachedEpochClock(); |
另外,Agrone 还提供了微秒和纳秒级的 API:
SystemEpochMicroClock基于java.time.InstantAPI 实现SystemEpochNanoClock基于java.time.InstantAPI 实现OffsetEpochNanoClock以定时采样的方式调用System.nanoTime()API,可以根据需要调整采样间隔和参数
三、RingBuffer
Aeron 的作者在 LMAX 任职期间,开发了 disruptor,点击这里查看相关文章。在 Agrona 中,作者也提供了这种数据结构的支持。
3.1 OneToOneRingBuffer
适用于单生产者单消费者的场景,和 Disruptor 中的 RingBuffer 不同,在定义 RingBuffer 大小时需要额外添加 RingBufferDescriptor.TRAILER_LENGTH,ByteBuffer API 决定在堆内还是堆外分配缓冲区。
下面代码中,展示了创建一个大小为 4096 的 OneToOneRingBuffer,采用堆外分配缓冲区:
1 | final int bufferLength = 4096 + RingBufferDescriptor.TRAILER_LENGTH; |
MessageHandler
消费数据时,需要实现 MessageHandler 接口,例如:
1 | public class MessageCapture implements MessageHandler { |
其中 msgType 字段是消息的标识,会存储在消息头中。如果不用这个字段的话,必须设置为大于 0 的值。
RingBuffer#write
生产数据时,需要调用 RingBuffer 的 write 方法,例如:
1 | //prepare some data |
sentOk 表示写入是否成功,利用这个可以进行背压操作,防止消费者消费不过来。RingBuffer 提供了下面两个方法来展示当前的生产和消费情况:
1 | //the current consumer position in the ring buffer |
ControlledMessageHandler
除了 MessageHandler 接口外 ControlledMessageHandler 也能够实现对 RingBuffer 的消费:
1 | public class ControlledMessageCapture implements ControlledMessageHandler { |
不同之处在于 onMessage() 方法返回 ControlledMessageHandler.Action:
- ABORT: This aborts the read operation for this message. It will be delivered again on next read
- BREAK: This stops further processing after the current message for this read.
- COMMIT: Continues processing, but commits at the current message.
- CONTINUE: Continues processing, committing at the end of the current batch (this is equivalent to the standard handler).
TryClaim
写入数据时,也可以通过 tryClaim() 方法可以直接操作 RingBuffer 底层的数据结构,如果使用常规的 write() 方法,需要把数据在对象中机械能拷贝,使用这种方式能省下拷贝的开销。
1 | int claimIndex = ringBuffer.tryClaim(1, Integer.BYTES); |
首先,调用 tryClaim() 以获取可以写入的索引,然后获取 RingBuffer 的底层数据结构,向其中写入数据最后,调用 commit 或 abort 结束。
3.2 ManyToOneRingBuffer
API 和 OneToOneRingBuffer 一致,支持多生产者的场景。
3.3 Broadcast
OneToOneRingBuffer 和 ManyToOneRingBuffer 都是在单消费者的场景,如果需要多消费者,Agrona 提供了 BroadcastTransmitter 和 BroadcastReceiver。
需要特别注意的是,在 Broadcast 下,如果发送方的生产速度快于消费者的消费能力,消息会被丢弃(没有背压支持)。
1 | private final BroadcastTransmitter transmitter; |
1 | public class ReceiveAgent implements Agent, MessageHandler { |
四、Data Structures
Agrona 提供了许多集合数据结构,用于解决基础数据类型在集合中需要装箱拆箱的开销。
4.1 HashMaps
使用 IDE 进行 DEUBG 时,Agrona HashMaps 可能会出现其中元素错误的问题。为了解决可以将构造方法中的 shouldAvoidAllocation 设置为 false, Agrona 将会关闭缓存功能,但这也会导致 GC 的增加。
| Collection | Notes |
|---|---|
| Int2IntHashMap | <int, int> 的 HashMap |
| Int2NullableObjectHashMap | <int, nullable object> 的 HashMap,如果 value 为 null 的话,在集合内部会使用 NullReference 来标识。 |
| Int2ObjectHashMap | <int, object> 的 HashMap |
| Long2LongHashMap | <long, long> 的 HashMap |
| Long2NullableObjectHashMap | <long, nullable object> 的 HashMap,如果 value 为 null 的话,在集合内部会使用 NullReference 来标识。 |
| Long2ObjectHashMap | <long, object> 的 HashMap |
| Object2IntHashMap | <object, int> 的 HashMap |
| Object2NullableObjectHashMap | <object, nullable object> 的 HashMap |
| Object2ObjectHashMap | <object, object> 的 HashMap |
在使用这些 HashMaps 时,需要确保元素 hashCode() 的正确性,另外如果 hashCodes 冲突严重也会极大影响集合的性能。
4.2 Caches
| Collection | Notes |
|---|---|
| Int2ObjectCache | Cache with primitive int lookup to an object. Tuned for very small data structures stored within CPU cache lines. Typical sizes are 2 to 16 entries. Underlying storage is an array. |
| IntLruCache | 固定大小的缓存,当达到上限时,使用 LRU 策略清理过期缓存 |
4.3 HashSets
| Collection | Notes |
|---|---|
| IntHashSet | 基础 int 类型的 HashSet,自动扩容。 |
| ObjectHashSet | object 类型的 HashSet,自动扩容。 |
4.4 Others
| Collection | Notes |
|---|---|
| IntArrayList | 基础 int 类型的 ArrayList |
| IntArrayQueue | 基础 int 类型的 ArrayQueue |
| BiInt2ObjectMap | 将两个 int 类型组合成一个 key,value 为 object 的 Map |
五、Direct Buffer
Agrona 由于使用了 sun.misc.Unsafe 和 sun.nio.ch.SelectorImpl.selectedKeys API,导致 JVM 在启动时可能有打印关于非法反射访问的警告日志。如果要删除的化,添加 JVM 参数:--add-opens java.base/sun.nio.ch=ALL-UNNAMED --add-opens jdk.unsupported/sun.misc=ALL-UNNAMED
Agrona 定义了 DirectBuffer 接口在用于和 Aeron 交互,它有点类似于 Java NIO ByteBuffer,但更方便一些。
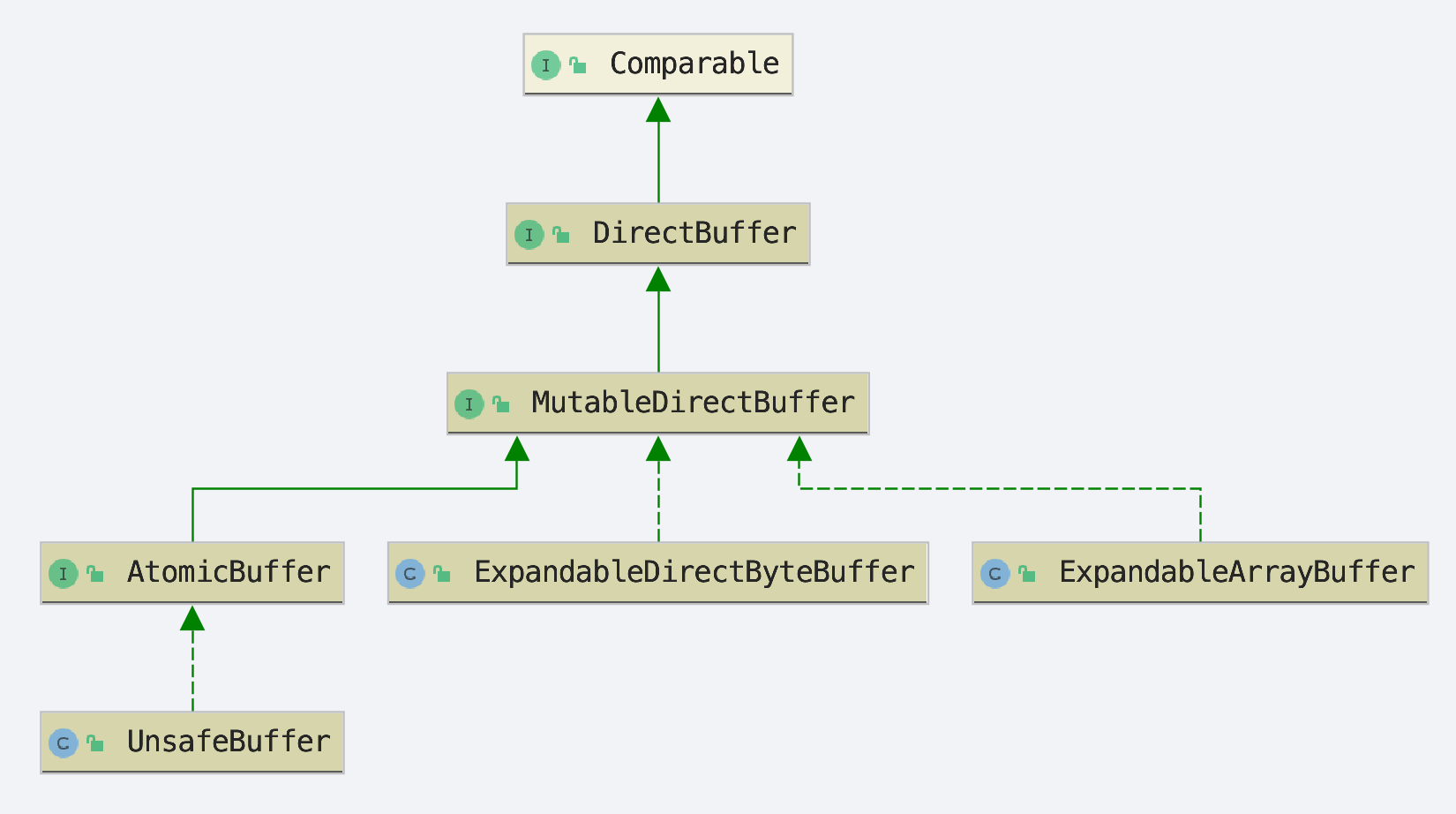
主要有以下三种实现:
| Name | Implementation Details |
|---|---|
| UnsafeBuffer | 堆外固定大小缓冲区,当超出大小时,会抛出 IndexOutOfBoundsException 异常。 |
| ExpandableDirectByteBuffer | 可扩容的直接缓冲区,底层使用 ByteBuffer 实现,默认为 128 字节,通过构造方法可以调整大小。当超出大小时,会创建一个新的 ByteBuffer 并将现有内容拷贝进去。 |
| ExpandableArrayBuffer | 底层使用字节数组(new byte[size])的直接缓冲区,默认为 128 字节,当超出大小时,会创建一个新的 byte[] 并将现有内容拷贝进去。 |
5.1 Key Concepts
Agrona 默认使用的字节序为 ByteOrder.nativeOrder() 的字节序,读写使用不同的字节序,会导致错误的结果。这可能出现在跨操作系统和跨平台的交互中。
下图是一个大小为 13 个字节的缓冲区,如果想要从中提取高亮部分的 4 个字节,我们需要先将 offset 设置为 4,再将读取长度设置为 4。

5.2 Working with Types
5.2.1 Chars & Bytes
DirectBuffer 提供了读写单个字节或 16 位字符的方法。
5.2.2 Shorts, Integers & Longs
DirectBuffer 提供了对 short、int、long 型数据的读写支持。对于 int 和 long,还额外提供了 compare-and-set、get-and-add、get-and-set 的工具方法。
1 | //place 41 at index 0 |
1 | //read current value while writing a new value. |
1 | //check the value was what was expected, returning true/false if it was. Then update the value a new value |
5.2.3 Floats & Doubles
通常不推荐使用 float 和 double 进行数据传输,要么使用格式化为字符串的 BigDecimal,要么使用缩放后的 long。
DirectBuffer 提供了读写 float 和 double 的方法。
5.2.3 Strings
-
putStringAscii、putStringUtf8操作非固定长度字符串,效率较低 -
putStringWithoutLengthAscii、putStringWithoutLengthUtf8操作固定长度字符串
六、IdGenerator
Agrona 也实现了雪花算法:
- 生成结果是 64 位数据
- 数据是大致有序的
- 每秒最多可生成 4096000 个。如果试图生成超出这个数值,则会自旋到下一个可生成的时间
- 如果系统出现时钟回拨,可以抛出
IllegalStateException异常 - 无锁和线程安全
初始化雪花算法时,需要提供一个唯一的节点 ID,默认情况下最多支持 1024 个节点。
1 | final long nodeId = 1L; |
需要注意的是,默认情况下它使用 1970 年作为起点,因此最多只能生成到 2039 年(和 Epoch Time 类似)。它提供了一个重载的构造方法,用于指定起始的时间。
 wechat
wechat- alipay



