目前绝大多数公司的业务系统都是集群化部署,那么在新版本上线时,保证平滑稳定,尽量减少对线上用户的影响,就显得尤为重要。毕竟谁也不想看到,版本一发布,系统就宕机吧。
随着互联网技术的发展,目前业务发布已经基本形成蓝绿发布、灰度(金丝雀)发布、和滚动发布这三种发布策略。
一、蓝绿发布
蓝绿部署是一种以可预测的方式发布应用的技术,目的是减少发布过程中服务停止的时间。
简单来说,我们把整个服务集群分成两组(或更多组,为了显示蓝/绿,分为两组),一组认为是绿色,另一组认为是蓝色,此时通过 LB LIVE 都能够为用户提供服务。

准备另一个备用的 LB,称其为 LB STANDBY,将绿色的集群交由它处理,此时绿色集群已经无法处理用户请求。

此时将绿色集群进行版本升级,将服务由 V1 升级至 V2。

绿色集群完成版本升级后,通过人工测试、自动化测试的方式测试 V2 服务的稳定性。当测试完毕无误后,将绿色集群交回 LB Live 处理,此时绿色集群开始处理用户实际请求。

此时先不要急于将蓝色集群进行升级,应当观察绿色集群在线上的运行情况。实际平稳运行一段时间后,确认新版本没有问题后,再做下一步处理。如果出现问题,及时将绿色集群交回 LB STANDBY,避免对线上产生影响。
除此之外,由于线上系统同时运行着 V1、V2 两个版本,因此你需要保证下层的数据存储(数据库等)对于这两个版本都是能够兼容处理的。
确认新版本无误后,开始对绿色集群执行同样的部署策略。


V2 版本在 LB STANDBY 上升级完毕后,接回 LB LIVE。

以上就是蓝绿发布的流程,需要注意的是,在发布过程中,集群的处理能力将会下降(本例为下降50%),因此尽量在请求负载较低时候进行升级操作。
蓝绿部署中,还要注意一些细节:
- 需考虑数据库对新老版本的兼容性
- 需要提前考虑数据库与应用部署同步迁移和回滚的问题
- 在非隔离基础架构( VM 、 Docker 等)上执行蓝绿部署,蓝色环境和绿色环境有被摧毁的风险
二、灰度发布
灰度发布又称为金丝雀发布,之所以叫金丝雀。是因为金丝雀对瓦斯极敏感,因此矿井工人会携带金丝雀,以便及时发现危险。
灰度发布,既可以灰度机器,又可以灰度代码,首先我们先谈谈对机器的灰度。
假设我们有两台机器,我们先对其中一台机器升级新版本,在 Router 层(LB 或其他中间件)确保用户的请求不会被新版本机器所处理。
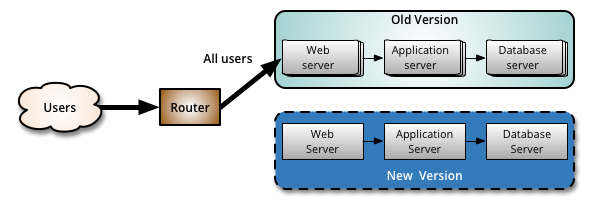
当新版本机器运行完毕后,我们通过一定策略,控制少量的用户访问新版本,绝大部分的用户仍然访问旧版本。
如下图所示,控制的策略主要是由 Router 层所处理的,例如通过配置内测用户、白名单、随机一小部分用户等方式,来达到只让一小部分访问新版本。
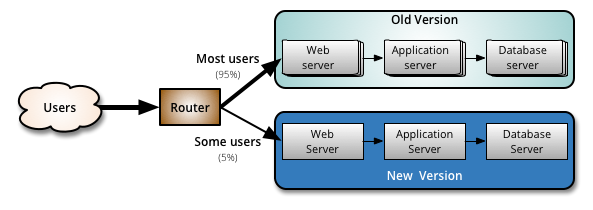
如果新版本出现问题,由于受影响的用户较少,处理起来困难不大。当新版本无误后,逐步放开用户访问新版本的比例,最后将用户全部从老版本切换到新版本。
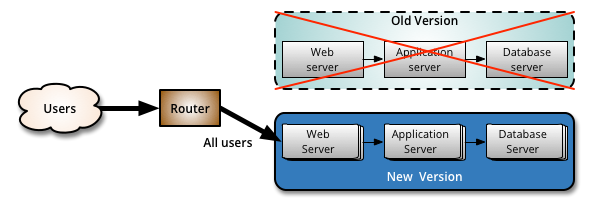
当切换完毕后,将原老版本机器升级到新版本,并使 Router 能够正常将用户分发到两台机器上。
以上就是通过灰度机器的方式进行系统升级,可以看到这种方式和蓝绿发布的区别是:蓝绿发布有一定的机器在升级过程中无法访问,而灰度发布是所有机器一直可以访问。
另一种灰度方式是对代码进行灰度,代码灰度要求在开发过程中,就要保证程序能够同时兼容新、旧两套逻辑。也就是说,在新版本功能基础上,还需要保证旧功能的可用。
新版本发布上线时,通过一种灰度方式,使得所有用户仍然都访问旧的逻辑。随后放开灰度的用户量,让少量用户能够执行新的业务逻辑。当运行一段时间无误后,逐步加大放开灰度的用户量,直至所有用户执行新的业务逻辑。最后将老的业务逻辑下线即可。
一些常用的灰度方式包括:
- 白名单方式(内部用户 or 外部用户、内测用户 or 非内测用户)
- 随机样本方式(对用户 ID 取模,例如取模5,一次灰度 1/5 的用户量)
- 用户特征方式(用户所处地区)
需要注意的是,如果新版本上线时,无法保证对旧业务逻辑的侵扰性,新版本的发布也可以采用蓝绿、灰度的方式发布。
三、滚动发布
滚动发布和对机器的灰度发布很像,简单来说,就是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。
首先对集群中小比例的机器进行新版本发布,主要做流量测试和代码测试使用。此时你可以登上该新版本的机器,查看 LOG,确保能够正常处理用户请求,且不出现程序错误。当新版本没有问题时,逐步将集群中的其他机器进行版本升级,直至所有机器都切换到新版本。
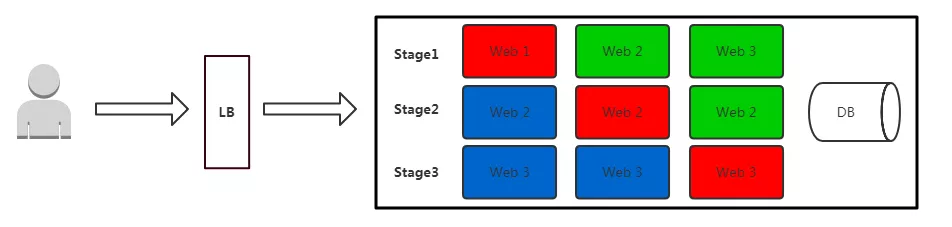
如上图所示,其中红色表示:正在升级的实例(不可访问);蓝色表示:升级完成的新版本实例(可访问);绿色表示:未升级的老版本实例(可访问)。
下面我列出滚动发布的一些特点:
- 对用户无感知,服务一直处于可用状态。
- 发布缓慢,要一批一批的手动发布。
- 如果出现问题,需要将所有机器进行回滚。
- 对 LB 有一定要求,要能够智能、及时的将实例加入或移出集群,当然目前主流的网关或 LB 中间件都能帮我们做到。
 wechat
wechat- alipay


