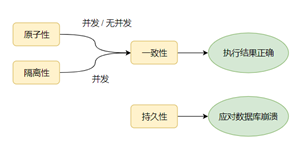
一、事务的四大特性 ACID
-
只有满足一致性,事务的执行结果才是正确的。
-
在无并发的情况下,事务串行执行,隔离性一定能够满足。此时要只要能满足原子性,就一定能满足一致性。
-
在并发的情况下,多个事务并发执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
-
事务满足持久化是为了能应对数据库奔溃的情况。
1.1 原子性 Atomicity
原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。比如在同一个事务中的SQL语句,要么全部执行成功,要么全部执行失败。
回滚可以用日志来实现,日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。
1.2 一致性 Consistency
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。 以转账为例子,A向B转账,假设转账之前这两个用户的钱加起来总共是2000,那么A向B转账之后,不管这两个账户怎么转,A用户的钱和B用户的钱加起来的总额还是2000,这个就是事务的一致性。
1.3 隔离性 Isolation
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务 T1 和 T2,在事务 T1 看来,T2 要么在 T1 开始之前就已经结束,要么在 T1 结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
1.4 持久性 Durability
一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
可以通过数据库备份和恢复来实现,在系统发生奔溃时,使用备份的数据库进行数据恢复。
二、并发一致性问题
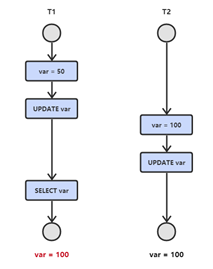
2.1 丢失修改
T1 和 T2 两个事务都对一个数据进行修改,T1 先修改,T2 随后修改,T2 的修改覆盖了 T1 的修改。
2.2 脏读
如果一个事务中对数据进行了更新,但事务还没有提交,另一个事务可以 “看到” 该事务没有提交的更新结果,这样造成的问题就是,如果第一个事务回滚,那么,第二个事务在此之前所 “看到” 的数据就是一笔脏数据。(脏读又称无效数据读出, 一个事务读取另外一个事务还没有提交的数据叫脏读。)
例子:
- Mary 的原工资为 1000, 财务人员将 Mary 的工资改为了 8000 (但未提交事务)
- Mary 读取自己的工资,发现自己的工资变为了 8000,欢天喜地!
- 而财务发现操作有误,回滚了事务,Mary 的工资又变为了1000
- 像这样,Mary记取的工资数8000是一个脏数据。
解决办法:
把数据库的事务隔离级别调整到 READ_COMMITTED
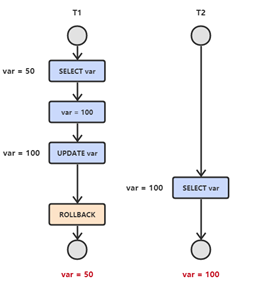
图解:
T1 修改一个数据,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2 读取的数据是脏数据。
2.3 不可重复读
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(同时操作,事务1分别读取事务2操作时和提交后的数据,读取的记录内容不一致。不可重复读是指在同一个事务内,两个相同的查询返回了不同的结果。 )
例子:
- 在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
- 在事务2中,这时财务人员修改了 Mary 的工资为 2000,并提交了事务
- 在事务1中,Mary 再次读取自己的工资时,工资变为了2000
解决办法:
如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。把数据库的事务隔离级别调整到REPEATABLE_READ
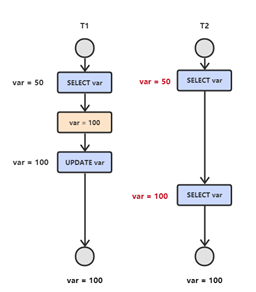
图解:
T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
2.4 幻读
事务 T1 读取一条指定的 Where 子句所返回的结果集,然后 T2 事务新插入一行记录,这行记录恰好可以满足T1 所使用的查询条件。然后 T1 再次对表进行检索,但又看到了 T2 插入的数据。 (和可重复读类似,但是事务 T2 的数据操作仅仅是插入和删除,不是修改数据,读取的记录数量前后不一致)。幻读的重点在于新增或者删除 (数据条数变化),同样的条件,第1次和第2次读出来的记录数不一样。
例子:
- 事务1,读取所有工资为 1000 的员工(共读取 10 条记录 )
- 这时另一个事务向 employee 表插入了一条员工记录,工资也为 1000
- 事务1再次读取所有工资为 1000的 员工(共读取到了 11 条记录,这就产生了幻读)
解决办法:
如果在操作事务完成数据处理之前,任何其他事务都不可以添加新数据,则可避免该问题。把数据库的事务隔离级别调整到 SERIALIZABLE_READ
图解:
T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
三、事务隔离级别
| 读数据一致性及允许的并发副作用隔离级别 | 读数据一致性 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| 未提交读 | 最低级别,只能保证不读取物理上损坏的数据 | Y | Y | Y |
| 已提交读 | 语句级 | N | Y | Y |
| 可重复读 | 事务级 | N | N | Y |
| 可序列化 | 最高级别,事务级 | N | N | N |
3.1 未提交读 Read Uncommitted
最低的隔离等级,允许其他事务看到没有提交的数据,会导致脏读。
3.2 已提交读 Read Committed
被读取的数据可以被其他事务修改,这样可能导致不可重复读。也就是说,事务读取的时候获取读锁,但是在读完之后立即释放(不需要等事务结束),而写锁则是事务提交之后才释放,释放读锁之后,就可能被其他事务修改数据。
该等级也是 SQL Server、Oracle 默认的隔离等级。
3.3 可重复读 Repeated Read
所有被选中获取的数据都不能被修改,这样就可以避免一个事务前后读取数据不一致的情况。但是却没有办法控制幻读,因为这个时候其他事务不能更改所选的数据,但是可以增加数据,即前一个事务有读锁但是没有范围锁,为什么叫做可重复读等级呢?那是因为该等级解决了下面的不可重复读问题。
该等级也是 MySQL 默认的隔离等级。
引申:现在主流数据库都使用 MVCC 并发控制,使用之后 RR(可重复读)隔离级别下是不会出现幻读的现象。
3.4 串行化 Serializable
所有事务一个接着一个的执行,这样可以避免幻读 (phantom read),对于基于锁来实现并发控制的数据库来说,串行化要求在执行范围查询的时候,需要获取范围锁,如果不是基于锁实现并发控制的数据库,则检查到有违反串行操作的事务时,需回滚该事务。
四、MyISAM VS InnoDB
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | N | Y |
| 事务 | N | Y |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表 | 行锁,操作时只锁某一行,不对其他行有影响 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还缓存真实数据,内存要求较高,且内存大小对性能有决定性的影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | Y | Y |
五、锁机制
5.1 乐观锁、悲观锁
1.乐观锁
顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。
乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
2.悲观锁
顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
5.2 表锁
1.表共享读锁(Table Read Lock)
对MyISAM表进行读操作时,它不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写操作。
2.表独占写锁(Table Write Lock)
对MyISAM表的写操作,则会阻塞其他用户对同一表的读和写操作。
5.3 行锁
1. 共享锁(S)
共享锁又称为读锁。若事务T对数据对象A加上 S 锁,则事务T可以读A 但不能修改A,其他事务只能再对A加 S 锁,而不能加X锁,直到T释放A上的 S 锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
2. 排他锁(X)
排它锁又称为写锁。若事务T对数据对象A加上 X 锁,则允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
3. 意向共享锁(IS)
表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先取得该表的 IS 锁。如果需要对记录 A 加共享锁,那么此时 InnoDB 会先找到这张表,对该表加意向共享锁之后,再对记录 A 添加共享锁。
4. 意向排他锁(IX)
类似上面,表示事务准备给数据行加入排他锁,也就是说事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。如果需要对记录 A 加排他锁,那么此时 InnoDB 会先找到这张表,对该表加意向排他锁之后,再对记录 A 添加排他锁。
六、索引
索引(Index)是帮助MySQL高效获取数据的数据结构,可以被理解为排好序的快速查找数据结构。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
我们通常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引、次要索引、覆盖索引、混合索引、前缀索引、唯一索引默认都是使用B+树索引,统称索引。
6.1 索引的特点
- 可以加快数据库的检索速度
- 降低数据库插入、修改、删除等维护的速度
- 只能创建在表上,不能创建到视图上
- 既可以直接创建又可以间接创建
- 可以在优化隐藏中使用索引
- 使用查询处理器执行SQL语句,在一个表上,一次只能使用一个索引
6.2 索引的优点
- 创建唯一性索引,保证数据库表中每一行数据的唯一性
- 大大加快数据的检索速度,这是创建索引的最主要的原因
- 加速数据库表之间的连接,特别是在实现数据的参考完整性方面特别有意义
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
- 通过使用索引,可以在查询中使用优化隐藏器,提高系统的性能
6.3 索引的缺点
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
- 索引需要占用物理空间,除了数据表占用数据空间之外,每一个索引还要占一定的物理空间,如果建立聚簇索引,那么需要的空间就会更大
- 当对表中的数据进行增加、删除和修改的时候,索引也需要维护,降低数据维护的速度
6.4 不会使用索引的时机
- 如果MySQL估计使用全表扫秒比使用索引快,则不适用索引。
1 | select * from table_name where key>1 and key<90; |
- 如果条件中有or,即使其中有条件带索引也不会使用。
1 | select * from table_name where key1='a' or key2='b'; |
- 复合索引,如果索引列不是复合索引的第一部分,则不使用索引(即不符合最左前缀)。
1 | select * from table_name where key2='b'; |
- 如果like是以 % 开始的,则该列上的索引不会被使用。
1 | select * from table_name where key1 like '%a'; |
- 如果列为字符串,则where条件中必须将字符常量值加引号,否则即使该列上存在索引,也不会被使用。
1 | select * from table_name where key1=1; |
6.5 适合建立索引的时机
- 为经常出现在关键字order by、group by、distinct后面的字段,建立索引。
- 在union等集合操作的结果集字段上,建立索引。
- 经常用作查询选择 where 后的字段,建立索引。
- 在经常用作表连接 join 的属性上,建立索引。
- 考虑使用索引覆盖。对数据很少被更新的表,如果用户经常只查询其中的几个字段,可以考虑在这几个字段上建立索引,从而将表的扫描改变为索引的扫描。
6.6 索引分类
6.6.1 单值索引
即一个索引只包含单个列,一个表可以有多个单值索引。
6.6.2 唯一索引
索引列的值必须唯一,但允许有空值。
6.6.3 联合索引
两个或更多个列上的索引被称作联合索引,联合索引又叫复合索引。对于复合索引:Mysql 从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
例如索引是key index (a,b,c),可以支持[a]、[a,b]、[a,b,c] 3种组合进行查找,但不支 [b,c] 进行查找。当最左侧字段是常量引用时,索引就十分有效。
七、JOIN
例如我们有两张表,Orders 表通过外键 Id_P 和 Persons 表进行关联。
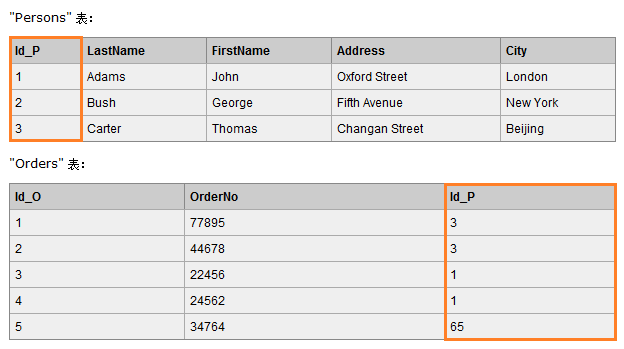
7.1 inner join
在两张表进行连接查询时,只保留两张表中完全匹配的结果集。
我们使用 inner join 对两张表进行连接查询,sql如下:
1 | SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo |
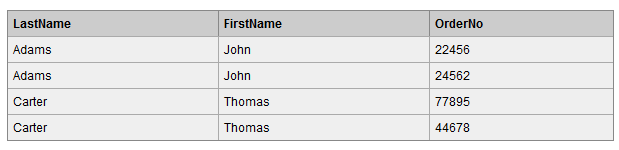
查询结果集如下,此种连接方式 Orders 表中 Id_P 字段在 Persons 表中找不到匹配的,则不会列出来。
7.2 left join
在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
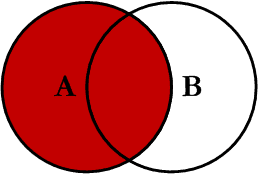
我们使用 left join 对两张表进行连接查询,sql如下:
1 | SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo |
查询结果如下,可以看到,左表(Persons表)中 LastName 为 Bush 的行的 Id_P 字段在右表(Orders表)中没有匹配,但查询结果仍然保留该行。

7.3 right join
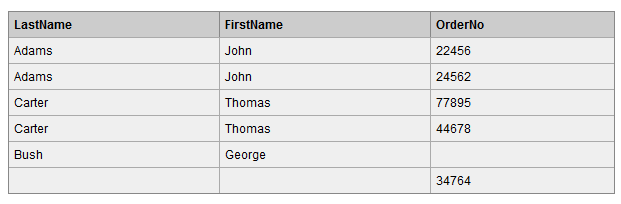
在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
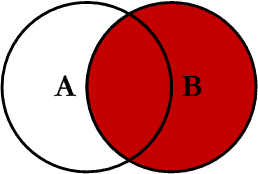
我们使用right join对两张表进行连接查询,sql如下:
1 | SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo |
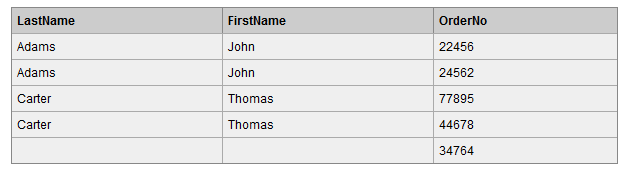
查询结果如下,Orders 表中最后一条记录 Id_P 字段值为 65,在左表中没有记录与之匹配,但依然保留。
7.4 full join
在两张表进行连接查询时,返回左表和右表中所有没有匹配的行。
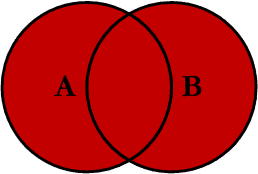
我们使用 full join 对两张表进行连接查询,sql如下:
1 | SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo |
查询结果如下,查询结果是 left join 和 right join 的并集。
 wechat
wechat- alipay


