一、引言
咳咳,这一节内容应该早就放上博客的,一直忘记了,在写上一篇《详解布隆过滤器》时,谈到缓存问题,一看博客中竟然没有写过相关的,实在是不该,特此补上。
Redis 所存在的缓存问题也是大部分缓存所存在的问题,因此本文不单单特指于 Redis。这些问题包括缓存穿透、缓存雪崩、缓存击穿、缓存预热等等,相关文章网络上已经数不胜数了,说实话本文和它们没啥不同之处,只是为了记录,所以对于了解过的人基本就是废话了,谨慎阅读哦。
二、缓存穿透
问题描述:
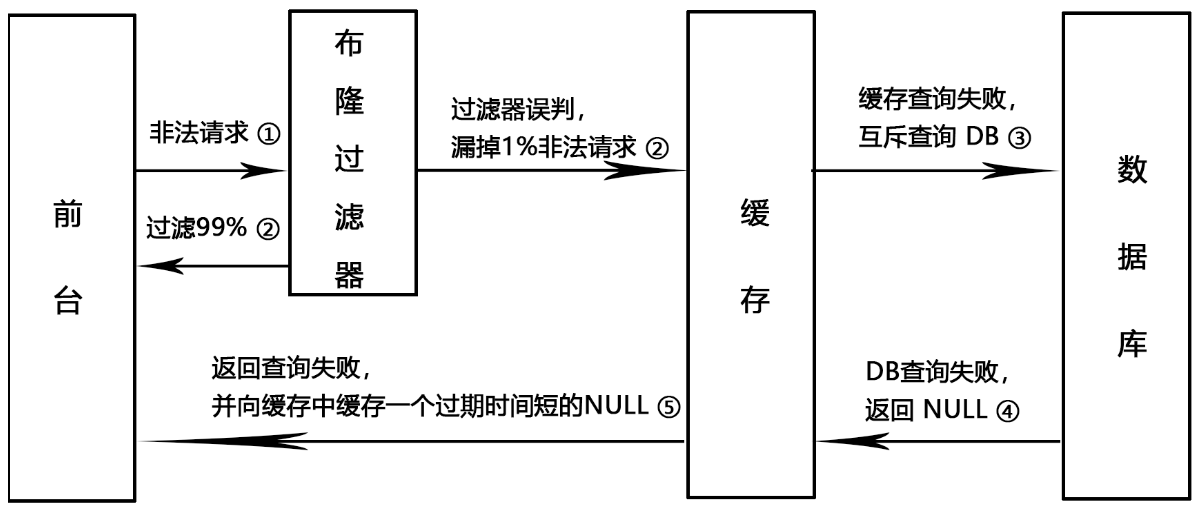
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。
解决方案:
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被 这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。
另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。
三、缓存雪崩
问题描述:
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
还可以将缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
四、缓存击穿
问题描述:
对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一 key 缓存,前者则是很多 key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个 key 有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端 DB 压垮。
解决方案:
业界比较常用的做法,是使用互斥锁(mutex)。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去 load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如 Redis 的 SETNX 或者 Memcache 的 ADD)去 set 一个 mutex key,当操作返回成功时,再进行 load db 的操作并回设缓存;否则,就重试整个 get 缓存的方法。
五、缓存预热
问题描述:
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方案:
- 直接写个缓存刷新页面,上线时手工操作下;
- 数据量不大,可以在项目启动的时候自动进行加载;
- 定时刷新缓存;
 wechat
wechat- alipay


