一、前言
在项目开发中,为提升系统性能,减少 IO 开销,本地缓存是必不可少的。最常见的本地缓存是 Guava 和 Caffeine,在 《详解 Guava Cache》中已经为大家介绍了 Guava,本篇文章将为大家介绍 Caffeine。
Caffeine 是基于 Google Guava Cache 设计经验改进的结果,相较于 Guava 在性能和命中率上更具有效率,你可以认为其是 Guava Plus。
毋庸置疑的,你应该尽快将你的本地缓存从 Guava 迁移至 Caffeine,本文将重点和 Guava 对比二者性能占据,给出本地缓存的最佳实践,以及迁移策略。
二、PK Guava
2.1 功能
| Feature | Guava | Caffeine |
|---|---|---|
| 自动加载实体到缓存中 | √ | √ |
| 自动回收 - 基于大小或时间的回收策略 - key 自动封装虚引用,value 自动封装弱/软引用 |
√ | √ |
| 自动刷新 | √ | √ |
| 实体过期或被删除的通知 | √ | √ |
| 统计累计访问缓存 | √ | √ |
| 异步 Cache | √ | |
| 写入外部资源 | √ |
从功能上看,Guava 已经比较完善了,满足了绝大部分本地缓存的需求。Caffine 除了提供 Guava 已有的功能外,同时还加入了一些扩展功能。
2.2 性能
Guava 中其读写操作夹杂着过期时间的处理,也就是你在一次 put 操作中有可能会做淘汰操作,所以其读写性能会受到一定影响。
Caffeine 在读写操作方面完爆 Guava,主要是因为 Caffeine 对这些事件的操作是异步的,将事件提交至队列(使用 Disruptor RingBuffer),然后会通过默认的 ForkJoinPool.commonPool(),或自己配置的线程池,进行取队列操作,然后再进行后续的淘汰、过期操作。
以下性能对比来自 Caffeine 官方提供数据:
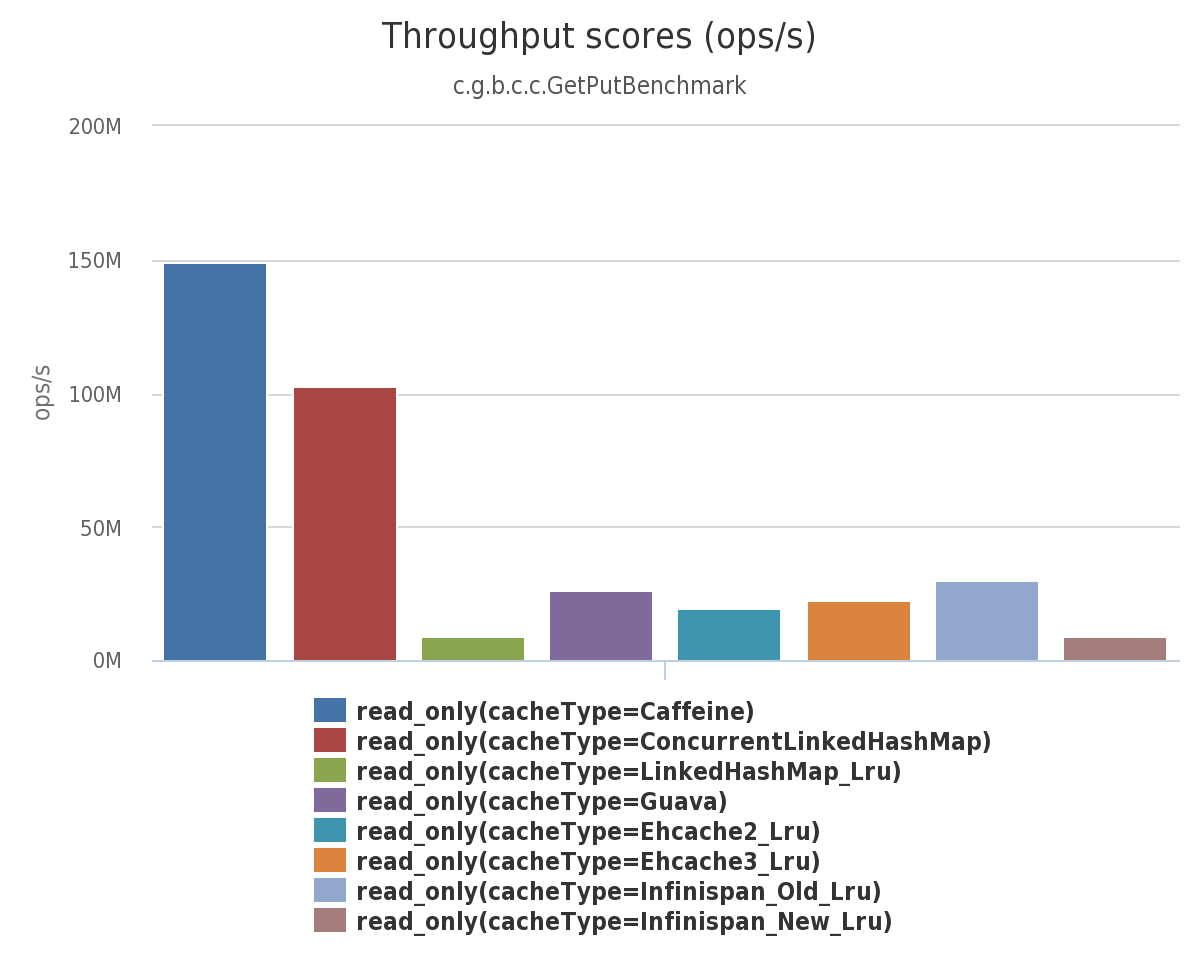
(1)在此基准测试中,从配置了最大大小的缓存中,8 个线程并发读:
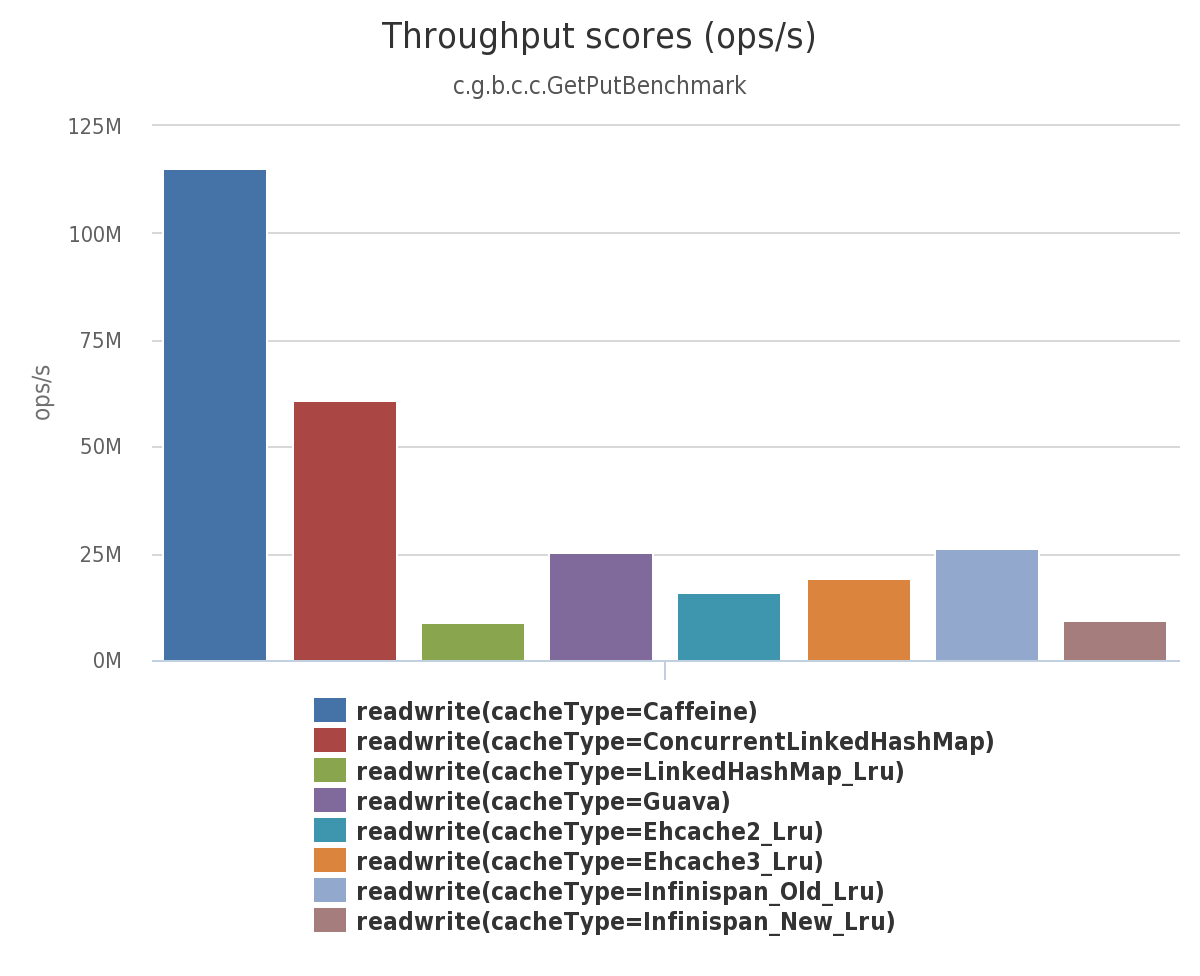
(2)在此基准测试中,从配置了最大大小的缓存中,6个线程并发读、2个线程并发写:
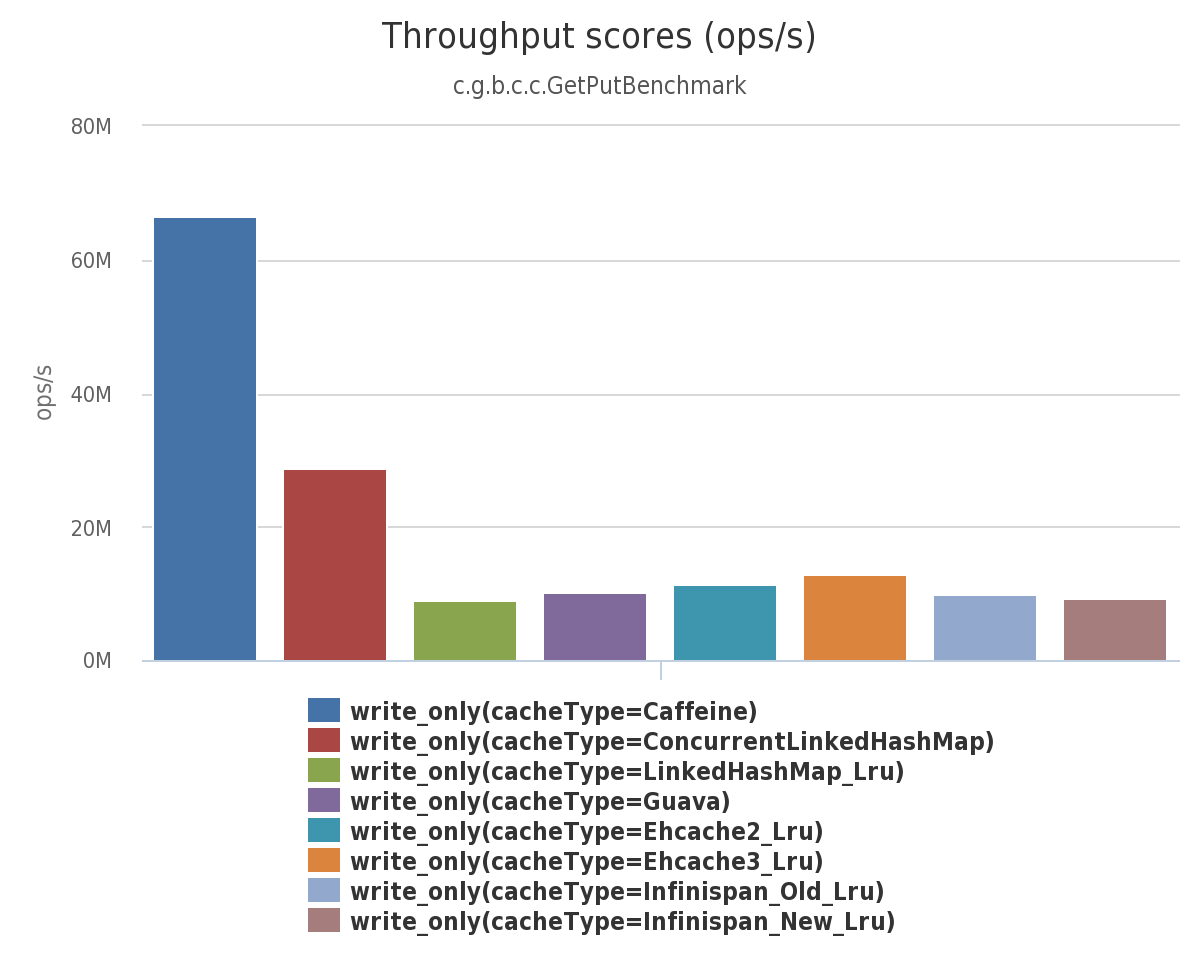
(3)在此基准测试中,从配置了最大大小的缓存中,8 个线程并发写:
2.3 命中率
缓存的淘汰策略是为了预测哪些数据在短期内最可能被再次用到,从而提升缓存的命中率。Guava 使用 S-LRU 分段的最近最少未使用算法,Caffeine 采用了一种结合 LRU、LFU 优点的算法:W-TinyLFU,其特点是:高命中率、低内存占用。
2.3.1 LRU
Least Recently Used:如果数据最近被访问过,将来被访问的概率也更高。每次访问就把这个元素放到队列的头部,队列满了就淘汰队列尾部的数据,即淘汰最长时间没有被访问的。
需要维护每个数据项的访问频率信息,每次访问都需要更新,这个开销是非常大的。
其缺点是,如果某一时刻大量数据到来,很容易将热点数据挤出缓存,留下来的很可能是只访问一次,今后不会再访问的或频率极低的数据。比如外卖中午时候访问量突增、微博爆出某明星糗事就是一个突发性热点事件。当事件结束后,可能没有啥访问量了,但是由于其极高的访问频率,导致其在未来很长一段时间内都不会被淘汰掉。
2.3.2 LFU
Least Frequently Used:如果数据最近被访问过,那么将来被访问的概率也更高。也就是淘汰一定时间内被访问次数最少的数据(时间局部性原理)。
需要用 Queue 来保存访问记录,可以用 LinkedHashMap 来简单实现一个基于 LRU 算法的缓存。
其优点是,避免了 LRU 的缺点,因为根据频率淘汰,不会出现大量进来的挤压掉老的,如果在数据的访问的模式不随时间变化时候,LFU 能够提供绝佳的命中率。
其缺点是,偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
2.3.3 TinyLFU
TinyLFU 顾名思义,轻量级LFU,相比于 LFU 算法用更小的内存空间来记录访问频率。
TinyLFU 维护了近期访问记录的频率信息,不同于传统的 LFU 维护整个生命周期的访问记录,所以他可以很好地应对突发性的热点事件(超过一定时间,这些记录不再被维护)。这些访问记录会作为一个过滤器,当新加入的记录(New Item)访问频率高于将被淘汰的缓存记录(Cache Victim)时才会被替换。流程如下:

尽管维护的是近期的访问记录,但仍然是非常昂贵的,TinyLFU 通过 Count-Min Sketch 算法来记录频率信息,它占用空间小且误报率低,关于 Count-Min Sketch 算法可以参考论文:pproximating Data with the Count-Min Data Structure
2.3.4 W-TinyLFU
W-TinyLFU 是 Caffeine 提出的一种全新算法,它可以解决频率统计不准确以及访问频率衰减的问题。这个方法让我们从空间、效率、以及适配举证的长宽引起的哈希碰撞的错误率上做均衡。
下图是一个运行了 ERP 应用的数据库服务中各种算法的命中率,实验数据来源于 ARC 算法作者,更多场景的性能测试参见官网:
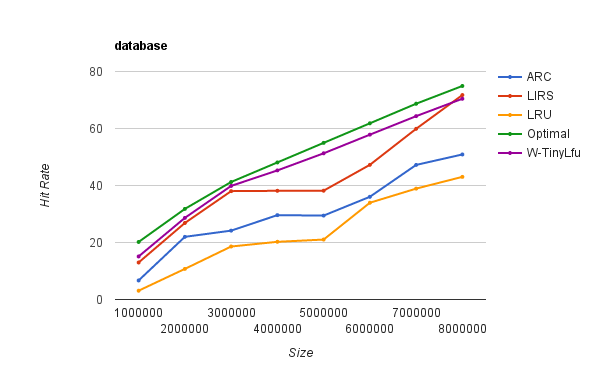
W-TinyLFU 算法是对 TinyLFU算法的优化,能够很好地解决一些稀疏的突发访问元素。在一些数目很少但突发访问量很大的场景下,TinyLFU将无法保存这类元素,因为它们无法在短时间内积累到足够高的频率,从而被过滤器过滤掉。W-TinyLFU 将新记录暂时放入 Window Cache 里面,只有通过 TinLFU 考察才能进入 Main Cache。大致流程如下图:

三、最佳实践
3.1 实践1
配置方式:设置 maxSize、refreshAfterWrite,不设置 expireAfterWrite
存在问题:get 缓存间隔超过 refreshAfterWrite 后,触发缓存异步刷新,此时会获取缓存中的旧值
适用场景:
- 缓存数据量大,限制缓存占用的内存容量
- 缓存值会变,需要刷新缓存
- 可以接受任何时间缓存中存在旧数据
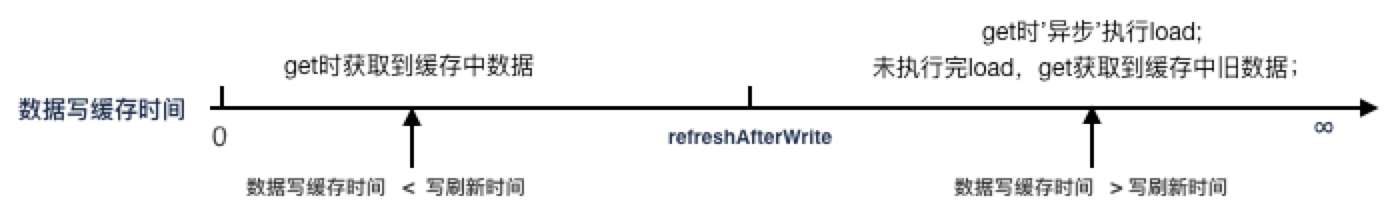
3.2 实践2
配置方式:设置 maxSize、expireAfterWrite,不设置 refreshAfterWrite
存在问题:get 缓存间隔超过 expireAfterWrite 后,针对该 key,获取到锁的线程会同步执行 load,其他未获得锁的线程会阻塞等待,获取锁线程执行延时过长会导致其他线程阻塞时间过长
适用场景:
- 缓存数据量大,限制缓存占用的内存容量
- 缓存值会变,需要刷新缓存
- 不可以接受缓存中存在旧数据
- 同步加载数据延迟小(使用 redis 等)

3.3 实践3
配置方式:设置 maxSize,不设置 refreshAfterWrite、expireAfterWrite,定时任务异步刷新数据
存在问题:需要手动定时任务异步刷新缓存
适用场景:
- 缓存数据量大,限制缓存占用的内存容量
- 缓存值会变,需要刷新缓存
- 不可以接受缓存中存在旧数据
- 同步加载数据延迟可能会很大

3.4 实践4
配置方式:设置 maxSize、refreshAfterWrite、expireAfterWrite,refreshAfterWrite < expireAfterWrite
存在问题:
- get 缓存间隔在 refreshAfterWrite 和 expireAfterWrite 之间,触发缓存异步刷新,此时会获取缓存中的旧值
- get 缓存间隔大于 expireAfterWrite,针对该 key,获取到锁的线程会同步执行 load,其他未获得锁的线程会阻塞等待,获取锁线程执行延时过长会导致其他线程阻塞时间过长
适用场景:
- 缓存数据量大,限制缓存占用的内存容量
- 缓存值会变,需要刷新缓存
- 可以接受有限时间缓存中存在旧数据
- 同步加载数据延迟小(使用 redis 等)

四、迁移指南
4.1 切换至 Caffeine
在 pom 文件中引入 Caffeine 依赖:
1 | <dependency> |
Caffeine 兼容 Guava API,从 Guava 切换到 Caffeine,仅需要把 CacheBuilder.newBuilder() 改成 Caffeine.newBuilder() 即可。
4.2 Get Exception
需要注意的是,在使用 Guava 的 get() 方法时,当缓存的 load() 方法返回 null 时,会抛出 ExecutionException。切换到 Caffeine 后,get() 方法不会抛出异常,但允许返回为 null。
Guava 还提供了一个 getUnchecked() 方法,它不需要我们显示的去捕捉异常,但是一旦 load() 方法返回 null 时,就会抛出 UncheckedExecutionException。切换到 Caffeine 后,不再提供 getUnchecked() 方法,因此需要做好判空处理。
 wechat
wechat- alipay


