一、基本概念
由于Elasticsearch也是基于Lucene实现,因此它的许多概念和Luncene相似,关于Lucene的知识,可以参考文章:《Lucene 初探——基于 Lucene 6.6.2》。
1.1 Node、Cluster
Elasticsearch本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
1.2 Index
Elasticsearch会索引所有字段,经过处理后写入一个倒排索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elasticsearch 数据管理的顶层单位就叫做 Index(索引),它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
1 | http://localhost:9200/_cat/indices?v |
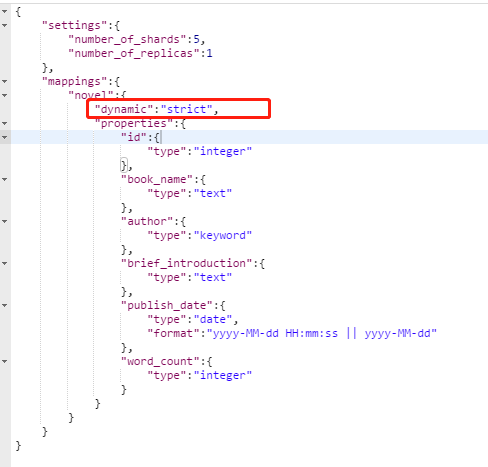
当我们插入数据的时候,如果有超出我们结构化的数据的时候,索引默认会自动更新数据,我们可以在创建索引时指定dynamic属性的默认值:
-
true:默认,可以自动创建索引,插入数据字段不符合的话就创建新的索引。
-
false:不自动创建索引,当插入数据不符合默认属性的时候,忽略新插入的不符合的字段的值。
-
strict:精确的,不允许插入不符合默认属性的值,如果不符合,直接报错。
1.3 Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示,下面是一个例子。
1 | { |
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
1.4 Type
Document 可以分组,比如某个 Index ,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。
性质完全不同的数据应该存成两个 Index,而不是一个 Index 里面的两个 Type。下面的命令可以列出每个 Index 所包含的 Type:
1 | http://localhost:9200/_mapping?pretty=true |
根据规划,Elasticsearch 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
1.5 文档字段属性
1.5.1 字段数据类型
字段的数据类型由字段的属性type指定,ElasticSearch支持的基础数据类型主要有:
-
字符串类型:keyword和text
-
keyword:数据类型用来建立电子邮箱地址、姓名、邮政编码和标签等数据类型,不需要进行分词。可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索。
-
text:Text 数据类型被用来索引长文本,这些文本会被分析,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。比如你配置了IK分词器,那么就会进行分词,搜索的时候会搜索分词来匹配这个text文档。但是:text 数据类型不能用来排序和聚合。
-
-
数值类型:字节(byte)、2字节(short)、4字节(integer)、8字节(long)、float、double;
-
布尔类型:boolean,值是true或false;
-
时间/日期类型:date,用于存储日期和时间;
-
二进制类型:binary;
-
IP地址类型:ip,以字符串形式存储IPv4地址;
-
特殊数据类型:token_count,用于存储索引的字数信息
1.5.2 字段的公共属性
-
index:该属性控制字段是否编入索引被搜索,取值为true或false。在5.X版本之前该属性共有三个有效值:analyzed、no和not_analyzed:-
analyzed:(默认属性)表示该字段被分析,编入索引,产生的token能被搜索到; -
not_analyzed:表示该字段不会被分析,使用原始值编入索引,在索引中作为单个词; -
no:不编入索引,无法搜索该字段;
-
-
store:指定是否将字段的原始值写入索引,默认值是no,字段值被分析,能够被搜索,但是,字段值不会存储,这意味着,该字段能够被查询,但是不会存储字段的原始值。 -
boost:字段级别的助推,默认值是1,定义了字段在文档中的重要性/权重; -
include_in_all:该属性指定当前字段是否包括在_all字段中,默认值是ture,所有的字段都会包含_all字段中;如果index=no,那么属性include_in_all无效,这意味着当前字段无法包含在_all字段中。 -
copy_to:该属性指定一个字段名称,ElasticSearch引擎将当前字段的值复制到该属性指定的字段中; -
doc_values:文档值是存储在硬盘上的索引时(indexing time)数据结构,对于not_analyzed字段,默认值是true,analyzed string字段不支持文档值; -
fielddata:字段数据是存储在内存中的查询时(querying time)数据结构,只支持analyzed string字段; -
null_value:该属性指定一个值,当字段的值为NULL时,该字段使用null_value代替NULL值;在ElasticSearch中,NULL 值不能被索引和搜索,当一个字段设置为NULL值,ElasticSearch引擎认为该字段没有任何值,使用该属性为NULL字段设置一个指定的值,使该字段能够被索引和搜索。
1.5.3 字符串类型常用的其他属性
-
analyzer:该属性定义用于建立索引和搜索的分析器名称,默认值是全局定义的分析器名称,该属性可以引用在配置结点(settings)中自定义的分析器; -
search_analyzer:该属性定义的分析器,用于处理发送到特定字段的查询字符串; -
ignore_above:该属性指定一个整数值,当字符串字段(analyzed string field)的字节数量大于该数值之后,超过长度的部分字符数据将不能被analyzer处理,不能被编入索引;对于 not analyzed string字段,超过长度的部分字符将被忽略,不会被编入索引。默认值是0,禁用该属性; -
position_increment_gap:该属性指定在相同词的位置上增加的gap,默认值是100; -
index_options:索引选项控制添加到倒排索引(Inverted Index)的信息,这些信息用于搜索(Search)和高亮显示:-
docs:只索引文档编号(Doc Number)
-
freqs:索引文档编号和词频率(term frequency)
-
positions:索引文档编号,词频率和词位置(序号)
-
offsets:索引文档编号,词频率,词偏移量(开始和结束位置)和词位置(序号)
-
默认情况下,被分析的字符串(analyzed string)字段使用positions,其他字段使用docs;
-
二、索引操作
2.1 结构化索引和非结构化索引
-
结构化索引:类似MySQL,我们会对索引结构做预定义,包括字段名,字段类型等
-
非结构化索引:类似Mongodb,索引结构未知,根据具体的数据来update索引的mapping
结构化相比非结构化,更易优化,性能好些;非结构化相较灵活,只是频繁update索引mapping会有一定的性能损耗。
本文下面的索引操作均是结构化索引,即指明了索引的具体结构。
2.2 创建索引
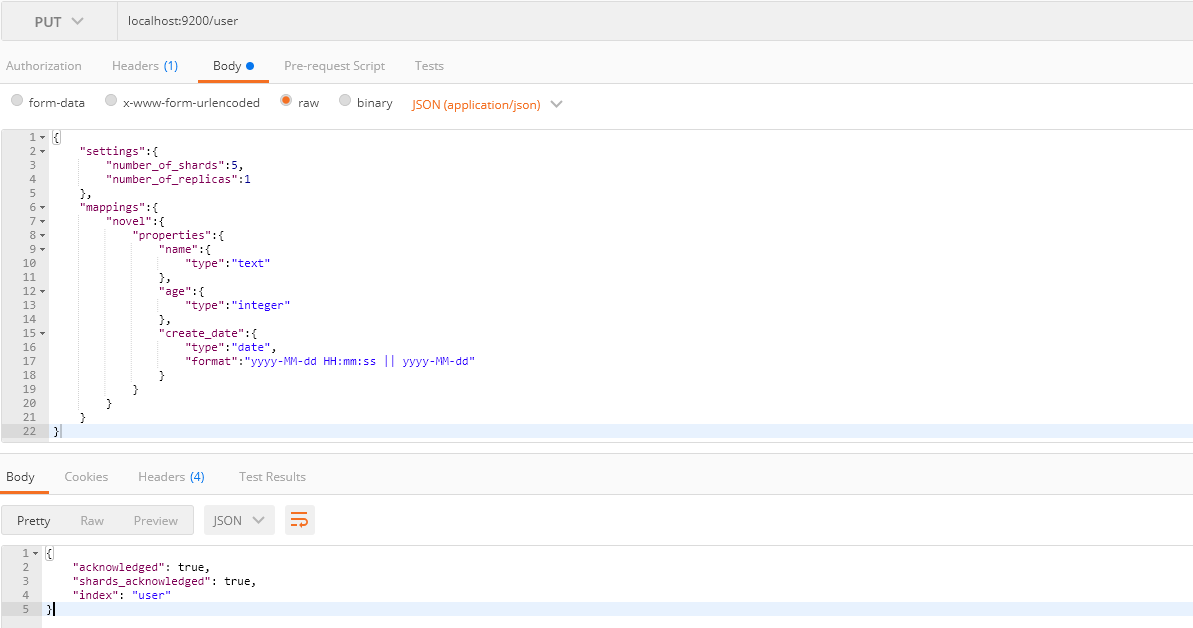
请求方式: PUT
请求路径: ES服务的IP:端口/要创建的索引名
假设我要创建一个user索引,拥有字段name、age、create_date,数据类型分别为字符串、数值、日期。那么请求内容如下:
1 | { |
响应内容如下:
1 | { |
2.3 删除索引
请求方式: DELETE
请求路径: ES服务的IP:端口/要删除的索引名
对于本例就是: DELETE localhost:9200/user,这里我就不演示了。
2.4 重建索引
如果你的索引后期要修改,那么你只能重建一个你要修改成的索引,然后将数据复制到新的索引中。
请求方式: POST
请求路径: ES服务的IP:端口/_reindex
1 | POST localhost:9200/_reindex |
三、数据操作
3.1 插入数据
当你创建的索引是非结构化的索引的时候,你可以随意插入你想要的字段作为属性。并且你每次插入的字段值可以是不一致的,索引会自动更新mapping,来适应数据。但是每次插入会耗费性能来做这些事情。
当你创建的索引是结构化的索引的时候,你如果插入的数据不符合你创建的mapping,那么也会自动更新mapping来适应你添加的数据,不会出现添加不上数据的情况。但是不建议这么做。
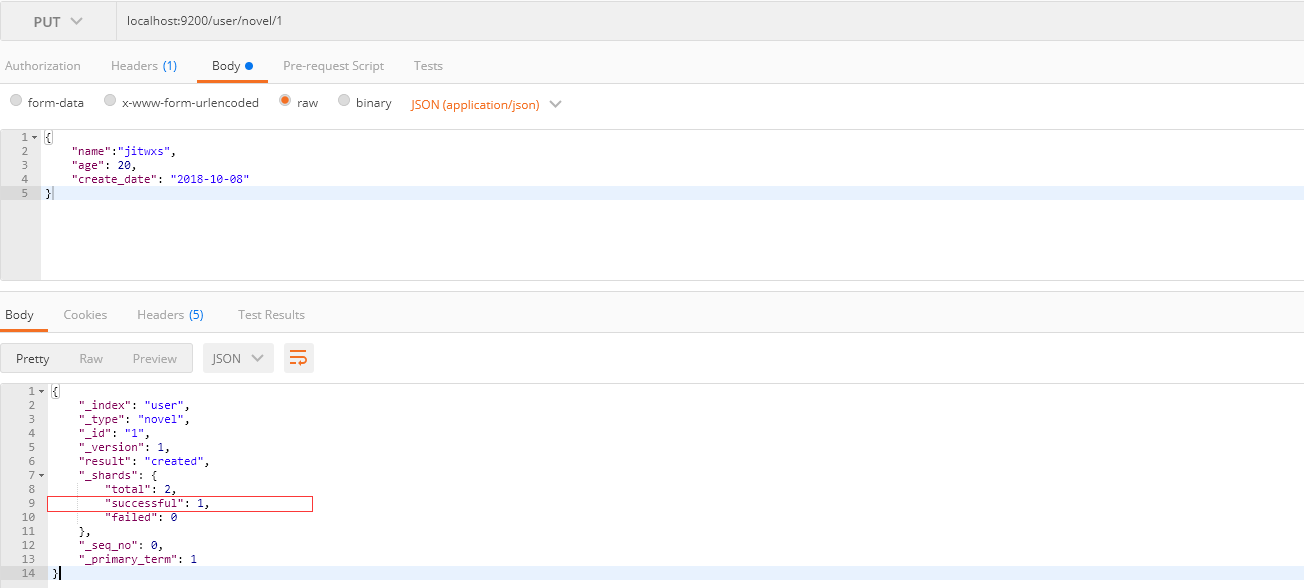
3.1.1 指定ID
请求方式: PUT
请求路径: ES服务的IP:端口/索引名/类型名/id
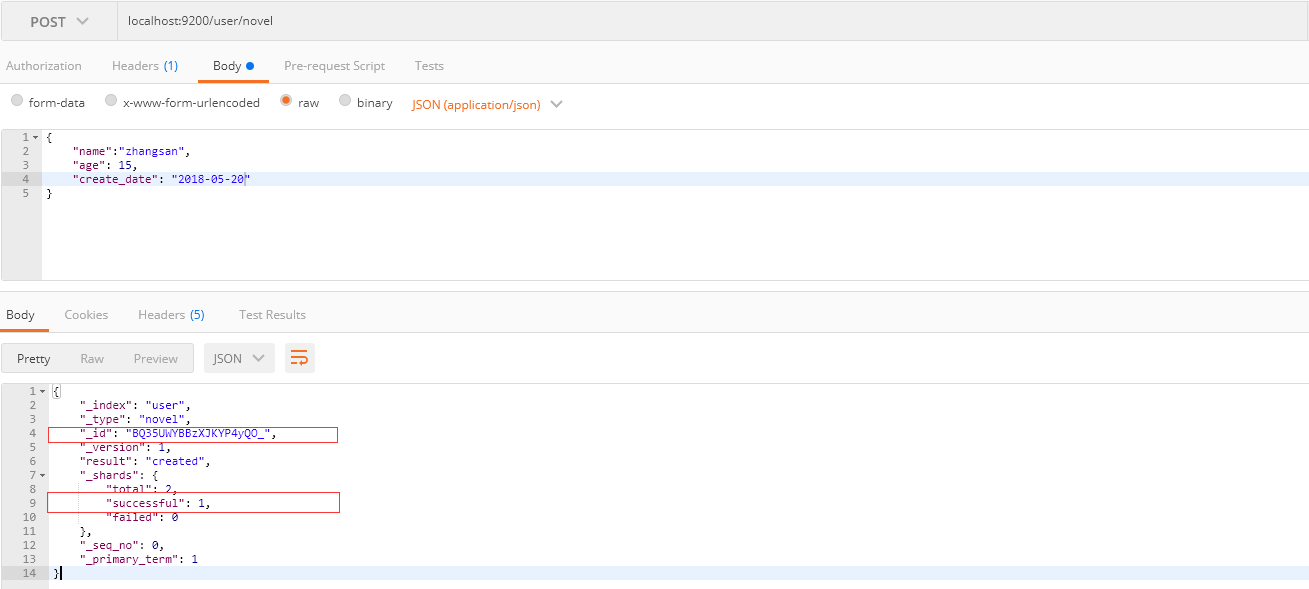
3.1.2 不指定ID
请求方式: POST
请求路径: ES服务的IP:端口/索引名/类型名
3.2 查看数据
请求方式: GET
请求路径: ES服务的IP:端口/索引名/类型名/ID
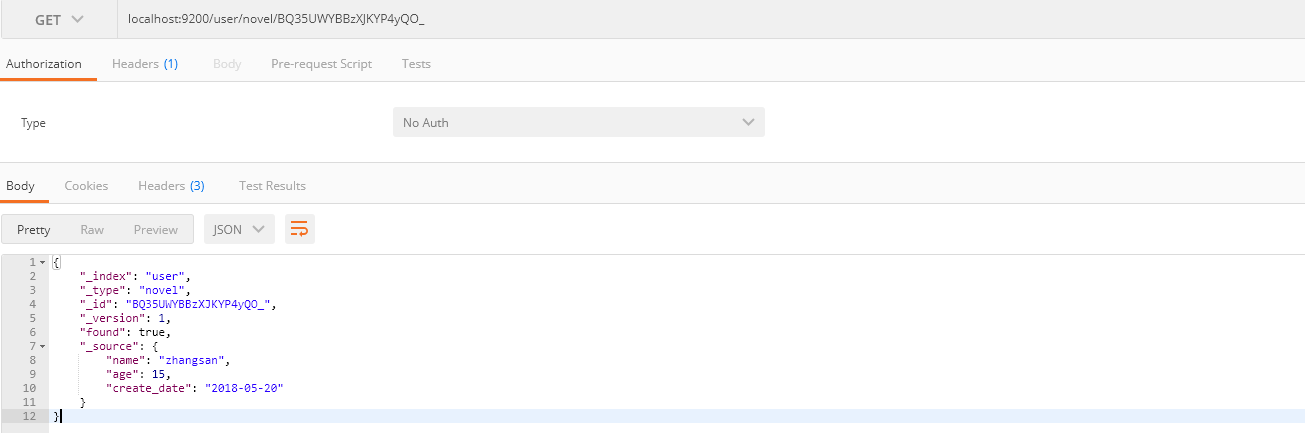
返回的数据中,found字段表示查询成功,_source字段返回原始记录。
3.3 修改数据
3.3.1 直接修改
请求方式: POST
请求路径: ES服务的IP:端口/索引名/类型名/ID/_update
请求体:
1 | { |
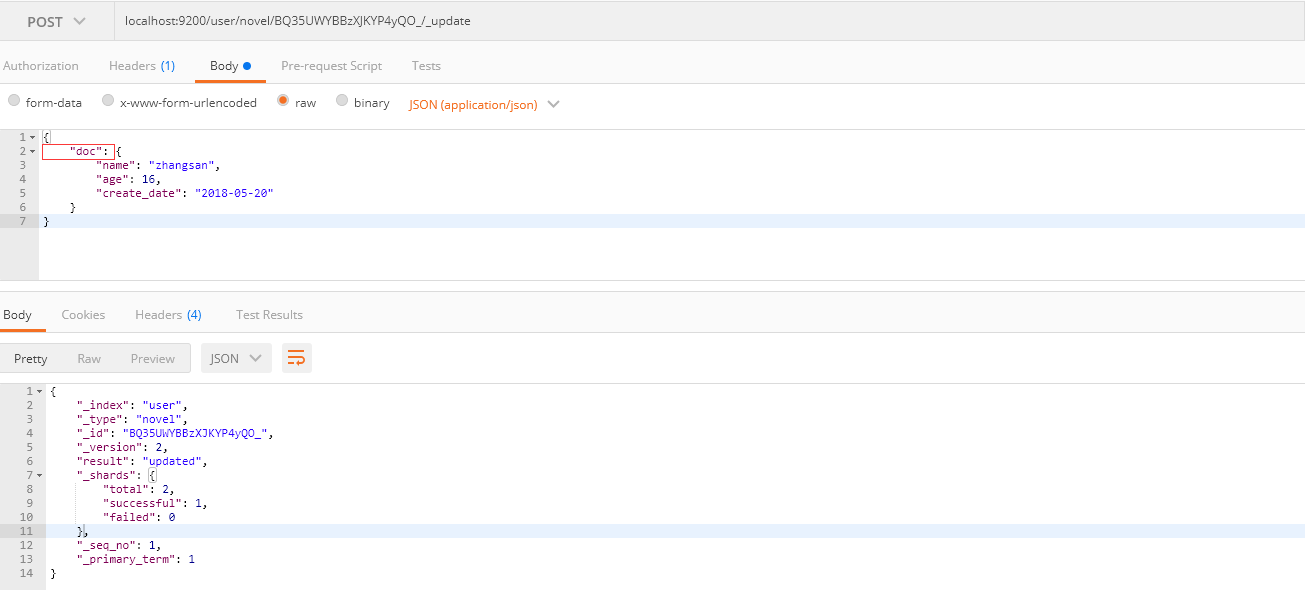
3.3.2 使用脚本修改
请求方式: POST
请求路径: ES服务的IP:端口/索引名/类型名/ID/_update
请求体:
1 | { |
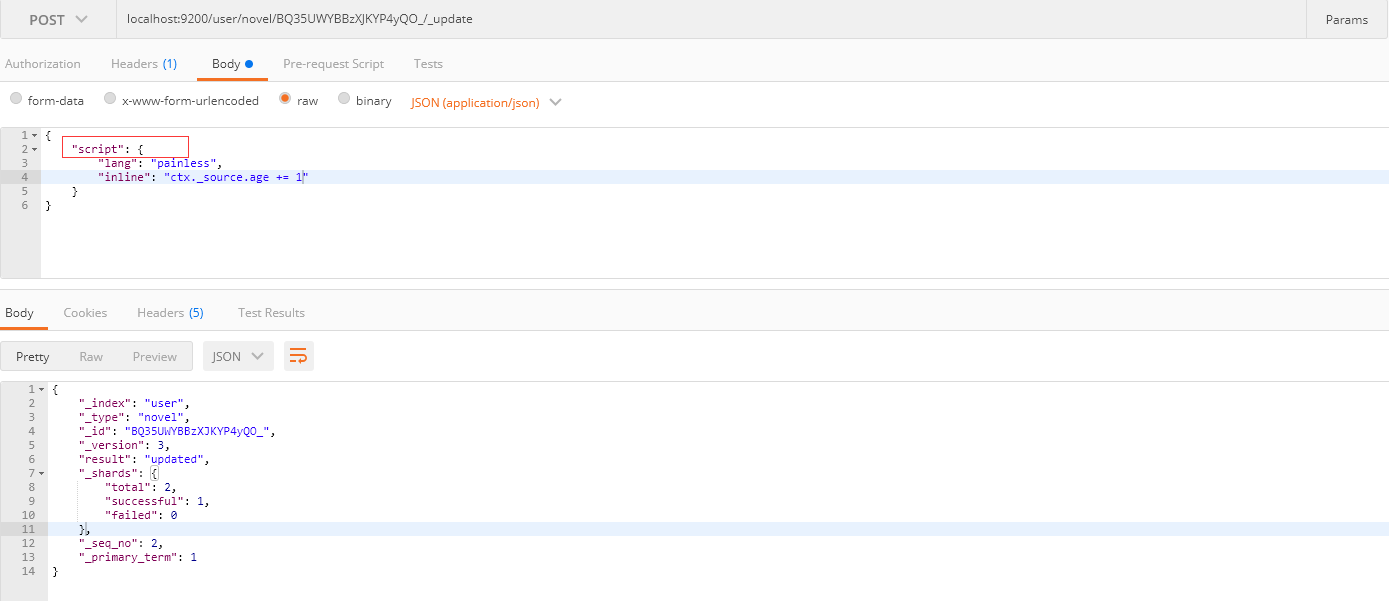
方法是POST,路径跟上面一致,需要注意的是,但是请求体的时候,使用的是script,,inline字段的值时可以对属性进行计算。
3.3.3 使用脚本并指定参数修改
请求方式: POST
请求路径: ES服务的IP:端口/索引名/类型名/ID/_update
请求体:
1 | { |
inline中的参数可以使用params中的参数。
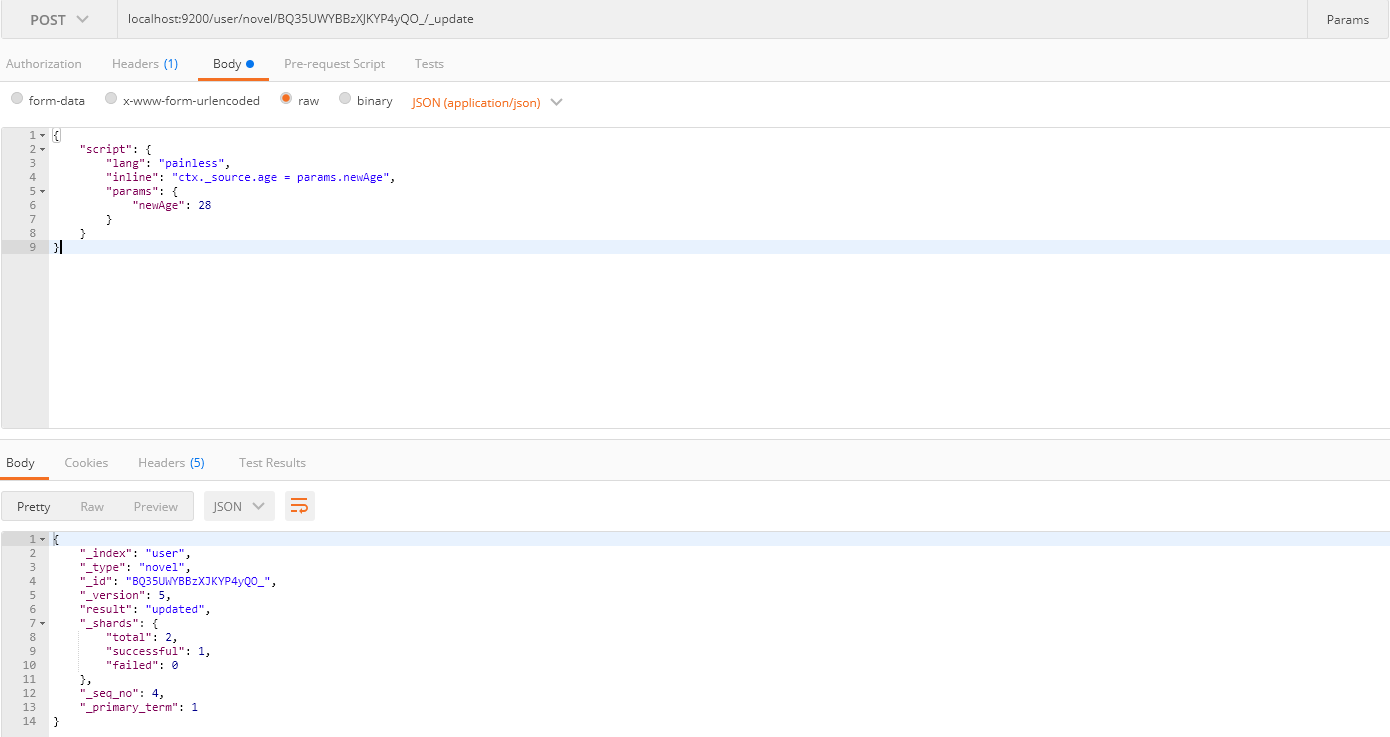
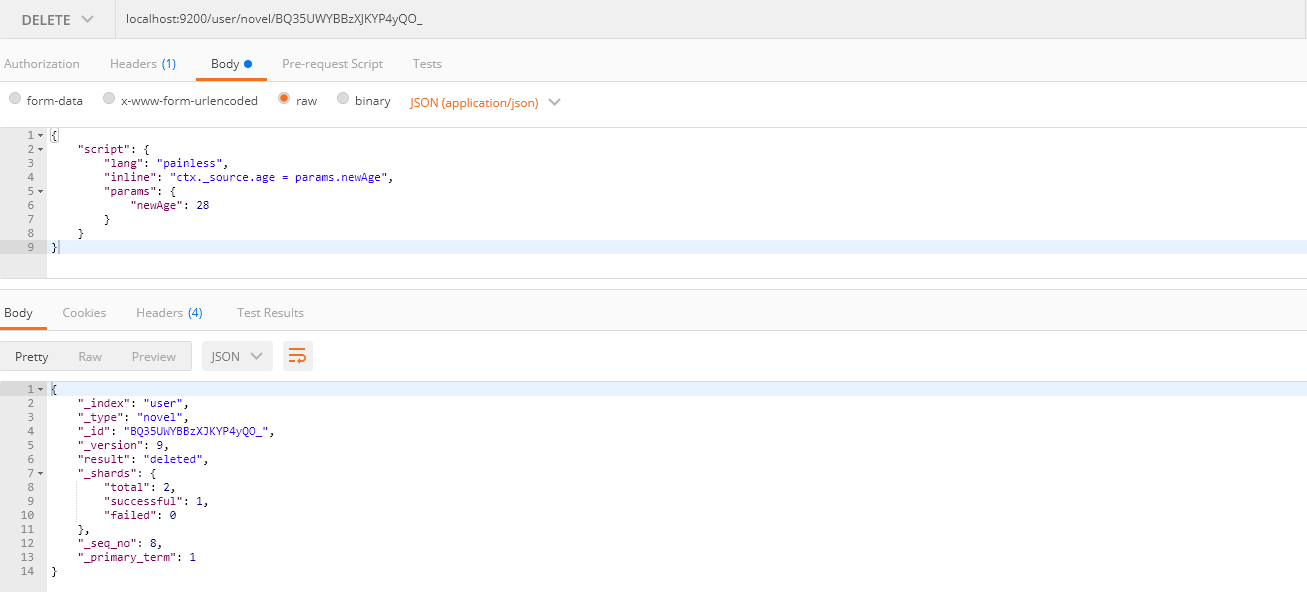
3.4 删除数据
请求方式: DELETE
请求路径: ES服务的IP:端口/索引名/类型名/ID
 wechat
wechat- alipay






