一、引言
Spring的事务机制包括声明式事务和编程式事务。
-
编程式事务管理:Spring推荐使用
TransactionTemplate,实际开发中使用声明式事务较多。 -
声明式事务管理:将我们从复杂的事务处理中解脱出来,获取连接,关闭连接、事务提交、回滚、异常处理等这些操作都不用我们处理了,Spring都会帮我们处理。
声明式事务管理使用了
AOP实现的,本质就是在目标方法执行前后进行拦截。在目标方法执行前加入或创建一个事务,在执行方法执行后,根据实际情况选择提交或是回滚事务。
声明式事务优点:不需要在业务逻辑代码中编写事务相关代码,只需要在配置文件配置或使用注解(@Transaction),这种方式没有侵入性。
声明式事务缺点:声明式事务的最细粒度作用于方法上,如果像代码块也有事务需求,只能变通下,将代码块变为方法。
事务属性包含以下五个方面:隔离级别、传播行为、回滚规则、事务超时、只读。
二、基本使用
首先在类中注入事务管理器,然后在需要实现事务的方法上添加 @Transactional 注解。通过调用 transactionManager 的 commit() 和 rollback() 实现事务提交和回滚。
1 |
|
2.1 TransactionManager
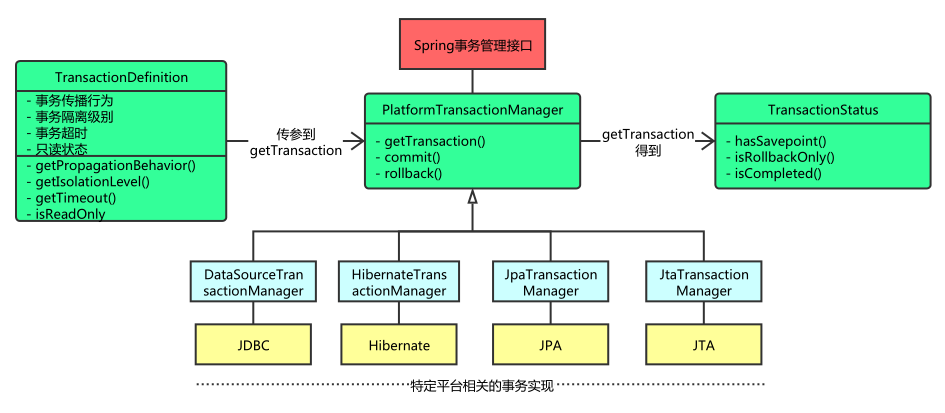
Spring 并不直接对事务进行管理,而是通过事务管理器接口 PlatformTransactionManager将事务职责委托给不同的 ORM 框架的事务来实现。通过这个接口,Spring 为 JDBC、JPA、Hibernate 等提供了不同的实现,常见的实现大致有以下几种。
| TransactionManager | Description |
|---|---|
| DataSourceTransactionManager | 适用 JDBC 或 iBatis(MyBatis) |
| HibernateTransactionManager | 适用 Hibernate 3 及以上版本 |
| JpaTransactionManager | 适用 JPA |
| JtaTransactionManager | 使用一个 JTA 实现来管理事务,在一个事务跨越多个资源时使用 |
HibernateTransactionManager 和 JpaTransactionManager 不再探讨,因为目前我使用的是原生 JDBC 或 MyBatis,因此没有了解过这两种事务管理器。
JtaTransactionManager 则是 Spring 对分布式事务管理的支持,如果项目采用多数据源,且要实现跨源事务,则需要了解下这个,可以参考文章:《JTA 深度历险 - 原理与实现》。
2.2 TransactionStatus
通过调用 transactionManager 的 getTransaction() 方法,可以得到 TransactionStatus,该接口用来记录事务的状态,它定义了一组方法,用来获取或判断事务的相应状态信息。
1 | public interface TransactionStatus{ |
2.3 事务接口联系
三、事务属性
3.1 隔离级别
隔离级别定义了一个事务可能受其他并发事务影响的程度。 数据库的不同隔离级别和带来的并发一致性问题参考文章:《数据库基础理论》第二、三节,这里不再赘述。
在Spring 中,预置了以下五种隔离级别:
| 隔离级别 | 含义 |
|---|---|
| ISOLATION_DEFAULT | 使用数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 |
| ISOLATION_READ_COMMITTED | 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 |
| ISOLATION_REPEATABLE_READ | 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生 |
| ISOLATION_SERIALIZABLE | 最高的隔离级别,完全服从ACID的隔离级别,确保阻止脏读、不可重复读以及幻读 |
可以看到预置的隔离界别和数据库的四大事务隔离级别是保持一致的,因此使用起来也比较方便,根据实际需要选择即可。
需要注意的是,如果你选择 ISOLATION_DEFAULT的话,你需要明确 SQL Server 的默认隔离级别是 READ_COMMITTED,MySQL 的默认的隔离级别是 REPEATABLE_READ。
1 | // 默认事务隔离级别 |
3.2 传播行为
如果在一个事务中调用了另一个事务,那么到底是新开一个事务,还是继续在这个事务内部处理,亦或是其他等等,这都是由传播行为所决定的。Spring 支持以下七种传播行为:
| 传播行为 | 含义 |
|---|---|
| PROPAGATION_REQUIRED | 当前方法必须运行在事务中。 如果当前存在事务,加入已存在的事务中,否则启动一个新事务。 |
| PROPAGATION_SUPPORTS | 当前方法支持运行在事务中。 如果当前存在事务,加入已存在的事务中,否则非事务运行。 |
| PROPAGATION_MANDATORY | 当前方法必须运行在事务中。 如果当前存在事务,加入已存在的事务中,否则抛出异常。 |
| PROPAGATION_REQUIRED_NEW | 当前方法必须运行在自己的事务中。 如果当前存在事务,挂起已存在的事务中,启动一个新事务执行。 |
| PROPAGATION_NOT_SUPPORTED | 当前方法不支持运行在事务中。 如果当前存在事务,挂起已存在的事务中,非事务运行。 |
| PROPAGATION_NEVER | 当前方法不能运行在事务中。 如果当前存在事务,抛出异常。 |
| PROPAGATION_NESTED | 类似于 PROPAGATION_REQUIRED_NEW,但前者是两个独立的事务,而它是嵌套事务。 |
1 |
以上传播行为基本都很易于理解,但其中 PROPAGATION_REQUIRED_NEW 和 PROPAGATION_NESTED 是最容易产生疑问的两种,下面了解下这两种传播行为。
3.2.1 PROPAGATION_REQUIRED_NEW
PROPAGATION_REQUIRES_NEW 启动一个新的,不依赖于环境的 “内部” 事务。这个事务将被完全 commited 或 rolled back 而不依赖于外部事务,它拥有自己的隔离范围, 自己的锁等等。当内部事务开始执行时,外部事务将被挂起, 内务事务结束时,外部事务将继续执行。
1 | ServiceA { |
以上面代码为例,由于 ServiceB#methodB 设置为 PROPAGATION_REQUIRES_NEW,它在执行时 ServiceA#methodA 的事务会被挂起。因此ServiceA#methodA 和 ServiceB#methodB 不会因为对方的执行情况而影响事务的结果,二者完全就是独立的两个事务。
3.2.2 PROPAGATION_NESTED
- PROPAGATION_REQUIRES_NEW starts a new, independent “inner” transaction for the given scope. This transaction will be committed or rolled back completely independent from the outer transaction, having its own isolation scope, its own set of locks, etc. The outer transaction will get suspended at the beginning of the inner one, and resumed once the inner one has completed.
Such independent inner transactions are for example used for id generation through manual sequences, where the access to the sequence table should happen in its own transactions, to keep the lock there as short as possible. The goal there is to avoid tying the sequence locks to the (potentially much longer running) outer transaction, with the sequence lock not getting released before completion of the outer transaction.
- PROPAGATION_NESTED on the other hand starts a “nested” transaction, which is a true subtransaction of the existing one. What will happen is that a savepoint will be taken at the start of the nested transaction. If the nested transaction fails, we will roll back to that savepoint. The nested transaction is part of of the outer transaction, so it will only be committed at the end of of the outer transaction.
Nested transactions essentially allow to try some execution subpaths as subtransactions: rolling back to the state at the beginning of the failed subpath, continuing with another subpath or with the main execution path there - all within one isolated transaction, and not losing any previous work done within the outer transaction.
For example, consider parsing a very large input file consisting of account transfer blocks: The entire file should essentially be parsed within one transaction, with one single commit at the end. But if a block fails, its transfers need to be rolled back, writing a failure marker somewhere. You could either start over the entire transaction every time a block fails, remembering which blocks to skip - or you mark each block as a nested transaction, only rolling back that specific set of operations, keeping the previous work of the outer transaction. The latter is of course much more efficient, in particular when a block at the end of the file fails.
——Author:Juergen Hoeller https://stackoverflow.com/questions/12390888
以上引用 Juergen Hoeller 的原文,根据他的描述,PROPAGATION_NESTED 开始一个 “嵌套的” 事务,它是已经存在事务的一个真正的子事务。 嵌套事务开始执行时,它将取得一个 savepoint,如果这个嵌套事务失败,将回滚到此 savepoint。嵌套事务是外部事务的一部分,只有外部事务结束后它才会被提交。
由此可见,两者的最大区别在于:PROPAGATION_REQUIRES_NEW 完全是一个新的事务,而 PROPAGATION_NESTED 则是外部事务的子事务,如果外部事务 commit,嵌套事务也会被 commit,,这个规则同样适用于 rollback.。
1 | ServiceA { |
还是以上面这段代码为例,那么实际上它就等价于:
1 | ServiceA { |
当初始执行 ServiceB.methodB() 这行代码时,将当前事务状态保存 SavePoint,当 ServiceB.methodB() 执行过程中出现异常导致子事务回滚,那么它会回滚到外部事务的 SavePoint 位置,外部事务可以根据业务场景去执行具体操作。
3.2.3 Spring 使用 PROPAGATION_NESTED
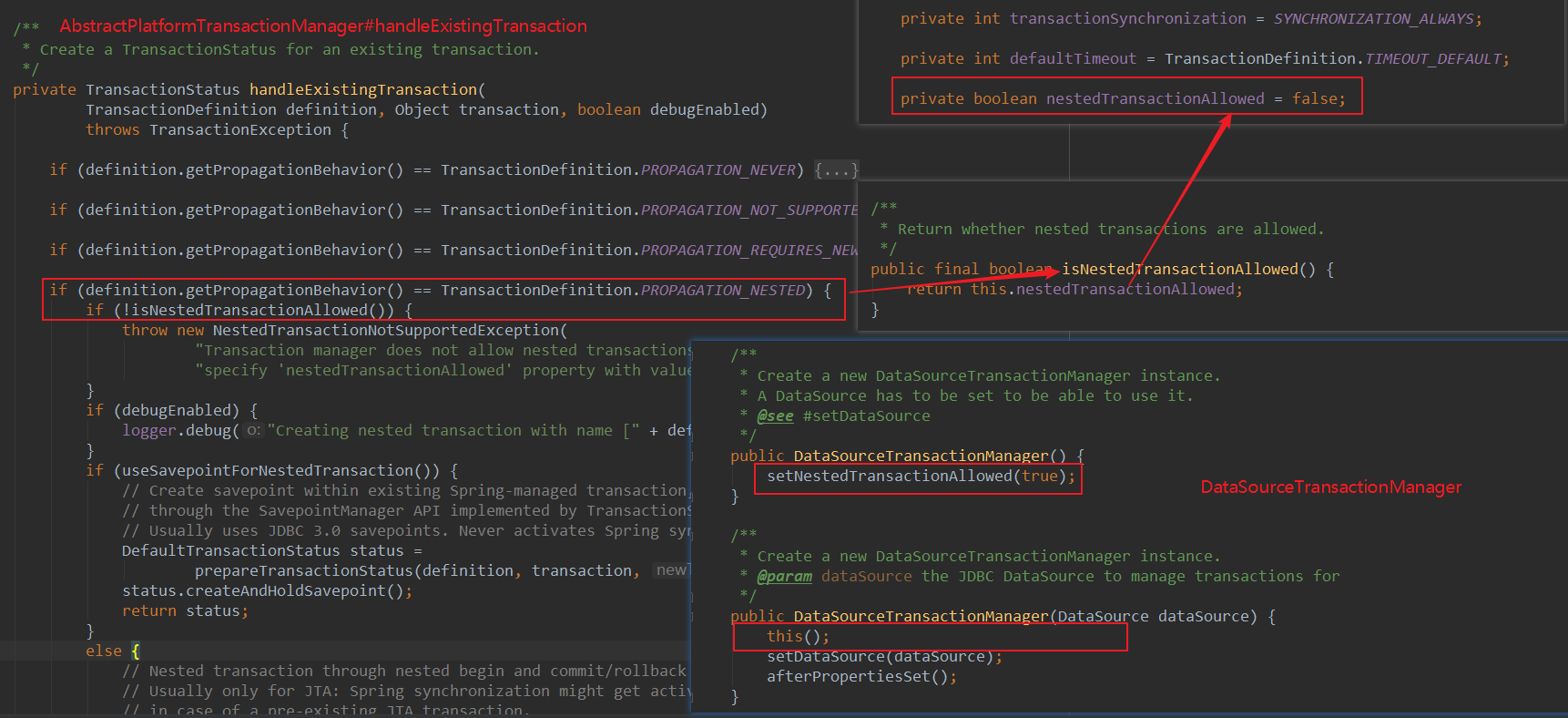
下面看下在 Spring 中是如何使用 PROPAGATION_NESTED 的,在 2.1 节中提到事务管理器接口 PlatformTransactionManager,Spring 对其有一个抽象的实现类 AbstractPlatformTransactionManager,它是 DataSourceTransactionManager 等事务管理器的父类。
进入 AbstractPlatformTransactionManager 的 handleExistingTransaction() 方法中,当我们的传播行为是 PROPAGATION_NESTED 时,先判断 nestedTransactionAllowed 是否为 true,根据下图可以看到该值默认为 false。不用担心的是在初始化 DataSourceTransactionManager 时,该值就被初始化为 true。
接着流程走,useSavepointForNestedTransaction() 的值永远为 true,因此进入 if 语句,status.createAndHoldSavepoint() 创建了一个 savepoint,下面追踪下创建的条件,如下图所示。
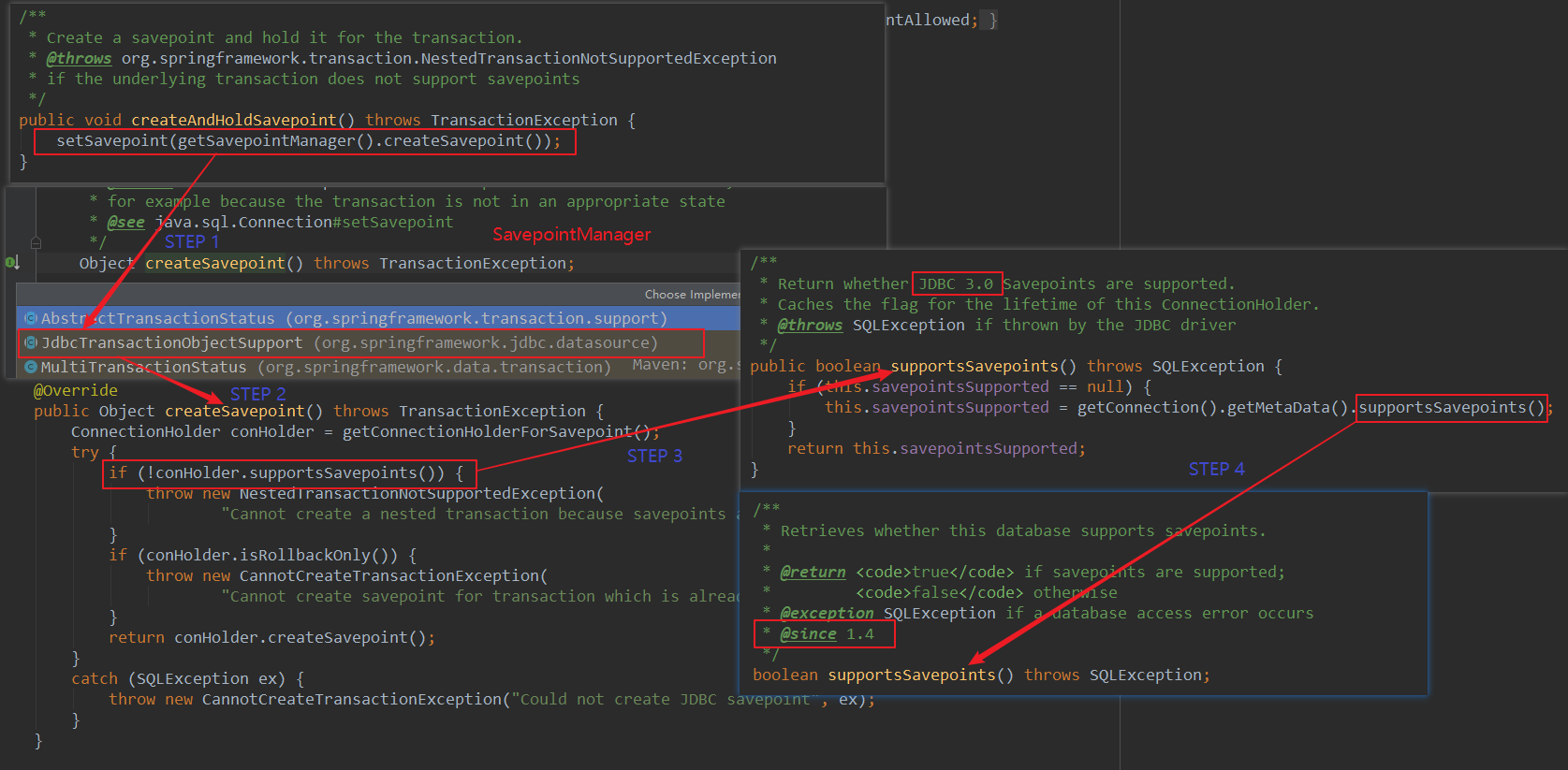
createAndHoldSavepoint() 方法内部通过调用 getSavepointManager().createSavepoint() 来创建一个 savepoint,进入 createSavepoint 方法,发现这是一个接口,因为我使用的是 DataSourceTransactionManager ,所以选择 JdbcTransactionObjectSupport 实现类。
在 createSavepoint() 方法中,首先判断当前 ConnectionHolder 是否支持 savepoint,点进去得知需要 JDBC Driver 3.0 + 且 JDK Version 1.4+。
3.3 回滚规则
通过配置当程序抛出指定异常时,自动回滚事务,通过指定 rollbackFor 指定异常类,通过指定 noRollbackFor 指定忽略的不会滚事务的异常。
1 | // 回滚异常 |
3.4 事务超时
为了使应用程序很好地运行,事务不能运行太长的时间。因为事务可能涉及对后端数据库的锁定,所以长时间的事务会不必要的占用数据库资源。
事务超时就是事务的一个定时器,在特定时间内事务如果没有执行完毕,那么就会自动回滚,而不是一直等待其结束。
1 | // 设定事务超时时间,单位:s,-1表示不设置 |
3.5 只读
如果事务只对数据库进行读操作,数据库可以利用事务的只读特性来进行一些特定的优化,例如优化掉不必要的锁操作等等。
1 | // 声明事务只读 |
在 MySQL 中,如果事务声明为只读,却在其中做修改操作,会抛出异常。

四、注意点
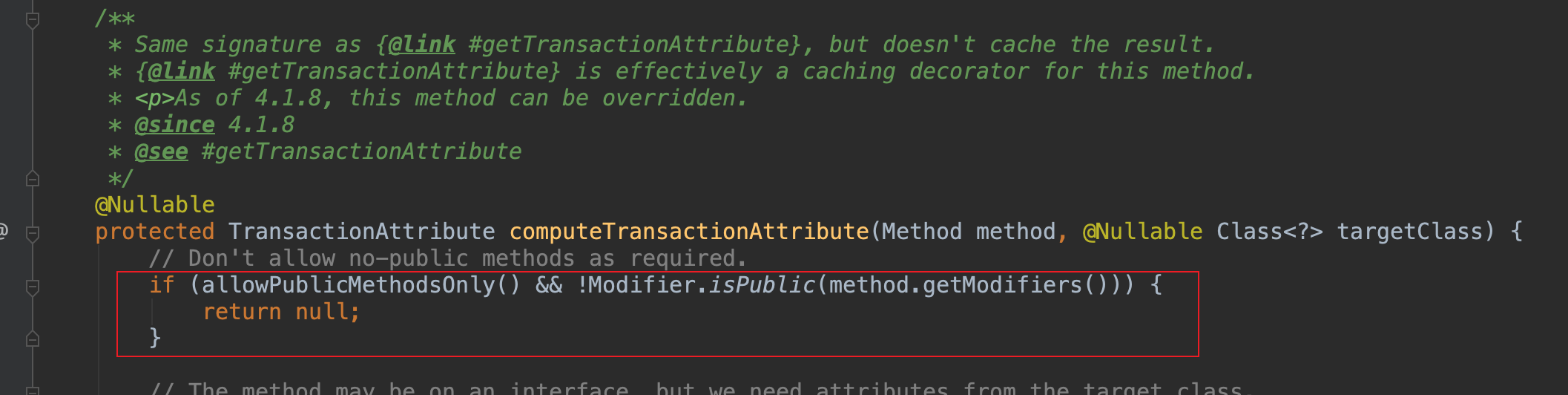
4.1 仅对 public 方法有效
只有 @Transactional 注解应用到 public 方法上才能进行事务管理。这是因为 Spring 在 AOP 事务注解时,在读取注解上的属性方法中,会优先判断方法是否是 public,如果不是 public,就不会读取事务配置信息。
4.2 AOP 的自调用问题
在 Spring 的 AOP 代理下,只有目标方法由外部调用,目标方法才由 Spring 生成的代理对象来管理。也就是说,在同一个类中的一个 @Transactional 方法中,去掉用另一个 @Transactional 方法,会导致第二个方法的事务无效,被 Spring AOP 所忽略。
1 |
|
 wechat
wechat- alipay



