一、引言
假设我们想要开发一个邮件系统,那么如何实现垃圾邮件的过滤呢。
最简单的办法就是把确定为是垃圾邮件的地址都保存起来,存入黑名单中。当用户接收到黑名单地址的邮件时,直接将邮件归类到垃圾箱中。
垃圾邮件的地址数量可能是巨大的,因此除了被存储在数据库中,程序实际使用的时候一定是需要借助缓存的。不论是使用本地缓存还是内存缓存,当数据量达到一定数量级时,都是不太合适的。
咳咳,如果你的数量级连百万都不到的话,那么其实布隆过滤器好像用处不大哈,缓存+容错处理似乎就能解决了。
假设存在 1000W 个垃圾邮件地址,每个地址就按 10 个字节来算,内存占用就已经达到 100MB 了。如果地址扩大到1亿个呢,内存占用就达到 1GB 了。
所以你是用 HashMap 还是用 Redis 的 Set 结构,亦或者其他来存储,可能都不太合适了。
二、布隆过滤器
2.1 基本特点
布隆过滤器(Bloom Filter),它的特点是:当它说某个 key 不存在时,key一定不存在;当它说某个 key 存在时,key 可能存在。
上面提到的只是一个为了引出布隆过滤器的例子,可能不太严谨。布隆过滤器的另一个主要应用是应对缓存穿透,缓存穿透指查询一个一定不存在的数据,因为缓存中数据不存在,出于容错考虑,会从数据库中读取数据。这将导致这个不存在的数据每次请求都要查询数据库,缓存相当于被绕过。在流量大或被恶意攻击时,缓存 IO 会急剧上升甚至导致宕机。
布隆过滤器就是应对缓存穿透的一个解决方案,首先将存在的数据都加载入布隆过滤器中,当查询一个不存在的数据时,布隆过滤器就会返回不存在,这样就能将无效的请求先行拦截掉。
由于布隆过滤器认为存在时,并不是一定存在,因此会存在一定的误判率。如果你不能够接受它的误判率,你应当在后续继续做处理,例如在缓存中查询为空时,缓存一个过期时间很短的空结果,来减低缓存穿透的风险。
如果你能够接受它的误判率,以引言中的垃圾过滤需求为例,可能会导致一些正常的邮件被归类到垃圾箱中。
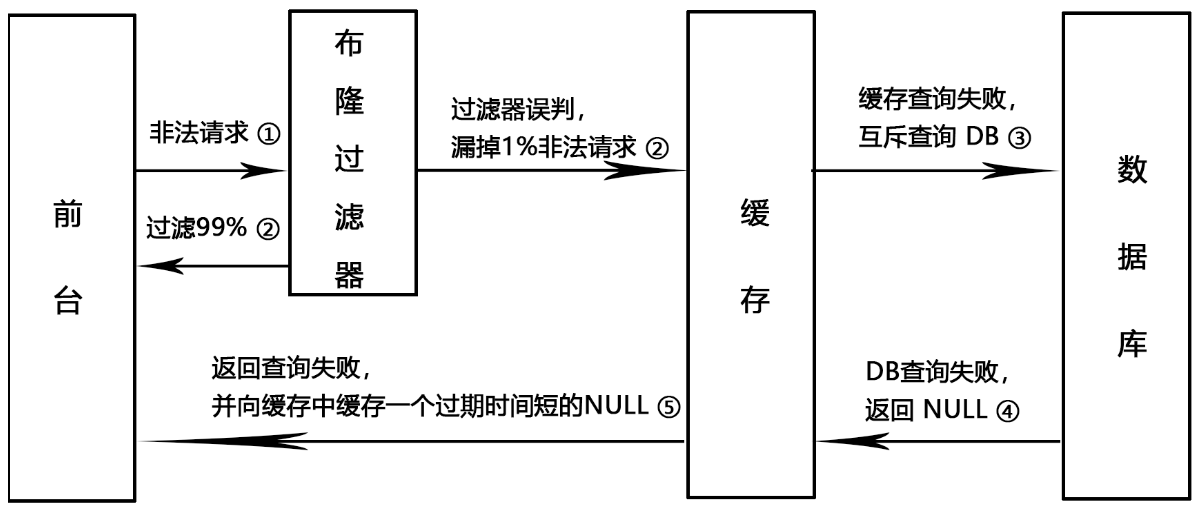
事先说明的是我目前在实际业务中并没有使用过布隆过滤器,因此有点纸上谈兵的味道。如果在今后实际项目中应用的流程和上图有出入的话,我会再更新下这张图。
上图是我画的布隆过滤器的一个使用图。在 ③ 步中,查询 DB 时应当采用互斥查询,避免导致缓存击穿问题,一个常见的互斥锁实现就是 Redis 的 setnx 指令。
需要注意的是,setnx 指令应当和 expire 指令同时设置,避免死锁问题。自 Redis 2.8 起,原生支持 setnx 和 expire 的原子性执行,无需再引用第三方分布式锁。用法例如:
1 | >sex lock:info true ex 5 nx # 设置一个叫做 lock:info 的 key,如果设置成功的话,同时设置过期时间为 5s |
在第 ⑤ 步中,对于不存在的记录,缓存一个过期时间短的值,这也是预防缓存穿透的一个办法。这样当下次该非法请求访问时,无需再查询 DB。
2.2 实现原理
了解了布隆过滤器的基本特点后,下面来了解下它的实现原理吧。布隆过滤器包含两大部分,一个位数组,以及多个无偏 Hash 函数。
以下图为例,最底下的就是布隆过滤器实际存储的一个位数组,而图中的 f、g、h 就是无偏 Hash 函数。当我们要存储元素 key1 时,将 key1 分别代入到每个 hash 函数,将哈希后的结果作为位数组的下标,并将该位置为 1。存储 key2 时同理。
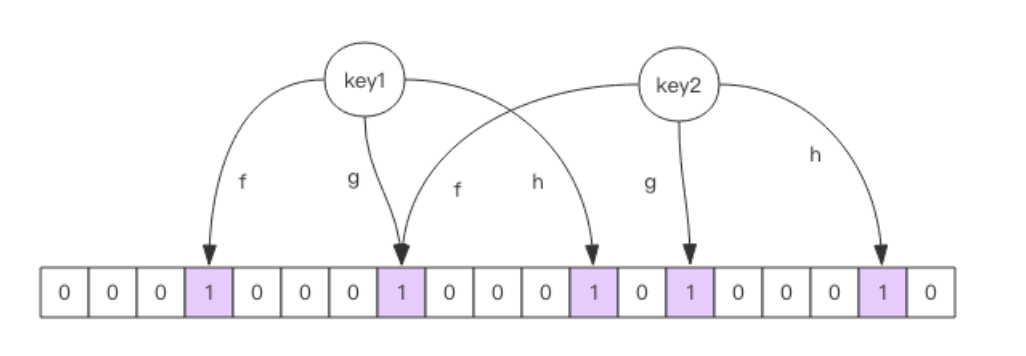
进行查询时,将查询值代入每一个 hash 函数,只有所有函数的返回结果在位数组中的值均为1,返回查询成功。只要有一个数组中值为 0,返回失败。
咳咳,写的我都嫌绕了。显而易见,如果布隆过滤器告诉你不存在,那么它肯定就不存在了,不然怎么会有某一个 hash 函数的值在位数组中不为 1 呢。
但是布隆过滤器告诉你存在,它却不一定存在。 因为当布隆过滤器中存储的数据越来越多,位数组的长度是有限的,那么就有可能多个不同的值哈希出来的值是一样的,就比如上图中的自左至右的第二个1其实就是两个不同的 key 哈希出相同的情况。
当 key 越来越多的情况下,就会出现某个 key 明明不存在,但是它在每个 hash 函数的结果都被其他 key 置为 1 的情况,这其实就是布隆过滤器误报的原因。
2.3 支持删除
了解了原理后,不难理解布隆过滤器是不支持元素删除的,因为位数组上的某一位有可能被多个 key 所公用。还是以上图为例,如果删除了 key1,把 key1 在位数组中的每一位置 0,那么 key2 查询时就变成不存在了。
想要解决这个问题,似乎得对数组每一位再来个计数,删除时计数删除,这样就会加大内存的占用。当然这也是我的纸上谈兵。
2.4 降低误判
如果让你来考虑,咋降低布隆过滤器的误判率呢,第一感觉就是让它的位数组变长一点不就好了。
不论我们使用哪种布隆过滤器的实现,基本上都可以显式的指定预计存放的元素个数,以及误判率。误判率设置的越低,那么所需的空间自然也就越大,具体设置多大跟你指定的元素个数也有关系。因此你应当合理的设置元素个数,不然一旦超出预设值,误判率就会升高,你可能就得考虑重建过滤器了。
2.5 空间占用
本节参考书籍:《Redis深度历险:核心原理和应用实践》,公式推倒过程如下比较复杂,有兴趣的可以看下这篇文章:《大数据量处理利器:布隆过滤器》
布隆过滤器根据预计元素数量 ,错误率 ,就能够计算出位数组的长度 ,也就是需要的存储空间大小(bit)。下面直接给出已经被证明的公式,hash 函数最佳数量 ,误判率 。
从公式中可以看出:
- 位数组相对越长 (m/n),错误率 f 越低,这个和直观上理解是一致的。
- 位数组相对越长 (m/n),hash 函数需要的数量也越多,影响计算效率。
当一个元素平均需要 1 个字节 (8bit) 的指纹空间时 (m/n=8),错误率大约为 2%
- 错误率为 10%,一个元素需要的平均指纹空间为 4.792 个 bit,大约为 5bit
- 错误率为 1%,一个元素需要的平均指纹空间为 9.585 个 bit,大约为 10bit
- 错误率为 0.1%,一个元素需要的平均指纹空间为 14.377 个 bit,大约为 15bit
如果你觉得计算困难的话,有第三方网站提供在线的布隆计算器:Bloom Calculator
当实际元素超出预计元素时,错误率会有多大变化,它会急剧上升么,还是平缓地上升,这就需要另外一个公式,引入参数 表示实际元素和预计元素的倍数:
当 t 增大时,错误率 f 也会跟着增大,分别选择错误率为 10%,1%,0.1% 的 k 值,画出它的曲线进行直观观察。
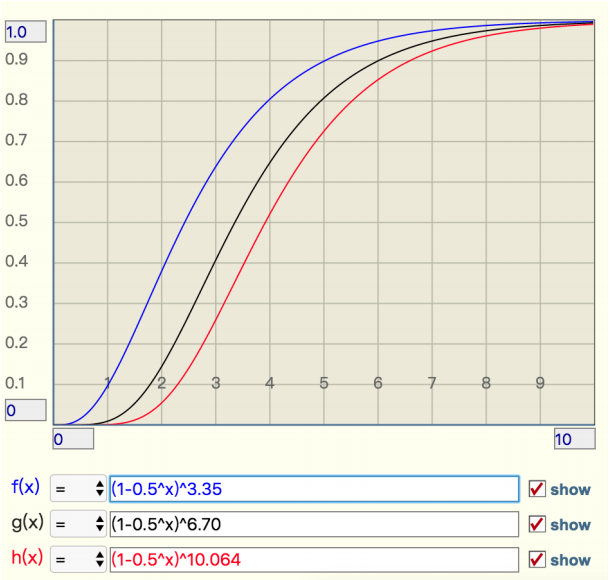
从这个图中可以看出曲线还是比较陡峭的:
- 错误率为 10% 时,倍数比为 2 时,错误率就会升至 40%
- 错误率为 1% 时,倍数比为 2 时,错误率升至 15%
- 错误率为 0.1%,倍数比为 2 时,错误率升至 5%
三、Java 中的布隆过滤器
Java 中的布隆过滤器常见的是 Guava 实现,在前几篇文章我介绍过 Guava 的 local cache,今天介绍下它的布隆过滤器。导入 Guava 依赖后,下面是一个简单的使用:
1 |
|
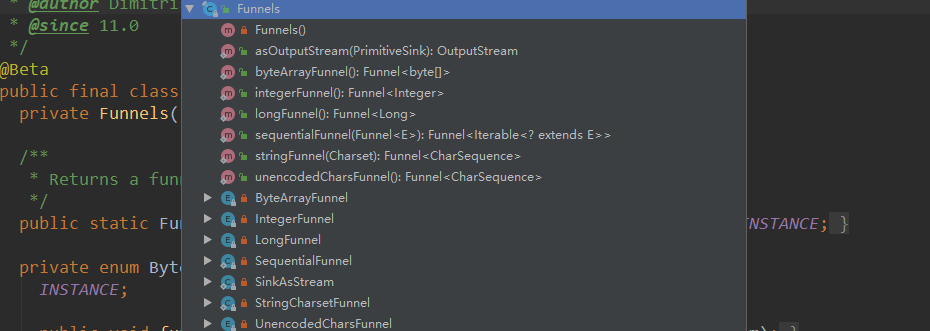
构建时第一个参数为布隆过滤器中元素类型,一个 Funnel 实现类,第二个参数为预估元素个数,第三个参数为误差率。我这里构建了一个整型的布隆过滤器,其他支持的类型,大致如下图所示。通过调用put 方法向过滤器添加值, mightContain() 方法判断是否存在过滤器中。
四、Redis 中的布隆过滤器
这里简单起见,只列出
redils-cli中的使用,第三方客户端命令自己百度下哈。
注意:
- Redis 支持布隆过滤器模块需要版本在 4.0+,之前版本需要使用第三方库,例如 orestes-bloomfilter 等等。
- Redis 的 Java 客户端中 Lettuce 早早就支持布隆过滤器指令,Jedis 则必须要在 3.0+ 版本才能使用。
自从 Redis 4.0 开始,引入了模块系统,使得布隆过滤器能够以插件的形式加入 Redis 中,参考文档:Quick Start。
文档中提供了两种方式,一种是以 Docker 方式,另一种就是编译插件的方式。如果你当前装有 Docker,那么使用 Docker 自然是最简单的。因为我这台机器上没有 Docker,因此采用编译插件方式,稍微复杂点。
有兴趣的同学可以看下我的这篇文章,回顾下动态库的知识:《Linux 静态库和动态库》
首先检查下版本,确保是 4.0 +,然后停止 Reids 服务:
1 | [root@VM_120_243_centos bin]# ./redis-cli --version |
然后就是将插件下载下来,并 make 编译,得到动态库:
1 | [root@VM_120_243_centos redis]# git clone https://github.com/RedisBloom/RedisBloom.git |
编译完毕后在当前文件夹下就会得到 redisbloom.so 这个动态库,即布隆过滤器的 Redis 模块。然后将其移动到合适的地方,这里我移动到了 Redis 配置文件的同级目录下:
1 | [root@VM_120_243_centos redis]# ls |
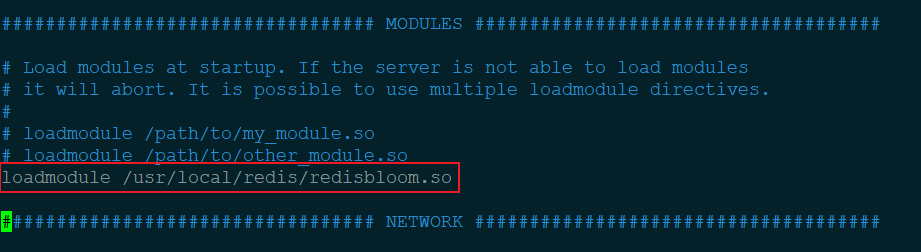
下一步就是将该插件在 Redis 配置文件中加载,编辑 redis.conf,找到 MODULES 那一块配置,将插件的路径写入:
注意: 这里的路径请使用绝对路径,我一开始用相对路径导致 Redis 无法启动。
配置完毕后启动 Redis 即可,布隆过滤器的基本使用如下,命令还是很简单的,就不再详细介绍了。
1 | 127.0.0.1:6379> bf.add codehole user1 |
最后补充下 Redis 中利用 bf.reserve 显式创建布隆过滤器,第一个参数为 key;第二个参数为错误率;默认为 0.01,第三个参数为预计大小,默认为 100。当 key 值存在时,创建失败。
1 | 127.0.0.1:6379> bf.reserve bloom 0.01 100 |
 wechat
wechat- alipay




