一、前言
本系列将为大家介绍如何对我们的 SpringBoot 应用程序进行监控和告警,使用的技术为 Prometheus + Grafana。二者均采用 Docker 进行安装部署,实际工作中自己在生产环境搭建的可能性不大,因此我们关注的重点放在如何使用就好了。
二、Prometheus
Prometheus 是 Soundcloud 开发的一款开源的监控工具,其本质是一个时间序列数据库(TSDB),采用 Go 语言开发。

它具有以下特点:
- 多维度:我们可以给指标数据添加多组标 Label,在展示时候可以作为筛选条件灵活选择。
- 拉模式:Prometheus 采用 Pull 模式,我们的指标数据生成后,Prometheus 会主动来消费,我们不需要做额外操作。
- 白盒&黑盒监控均支持:无论什么维度的指标数据,都可以采集到,对 DevOps 友好。
- Metrics & Alert:Prometheus 采集的是 Metrics 指标,而不是 logging 和 tracing。
- 社区生态丰富:支持各种语言的客户端,并且有各种各样的 exporters,来实现黑盒监控。例如 Redis,我们可以通过 Redis Exporters,来实现对 Redis 性能指标的监控。
2.1 架构设计
下图来源于 Promethues 官网,较为清楚的简述了 Prometheus 的架构。
在架构图的左侧,展示了 Prometheus 如何从指标提供方去拉取 Metrics。
(1)在架构图的左下角,我们一开始说到,Prometheus 采用拉的方式获取 Metrics。有些服务(例如 Spring 应用程序),可以通过在程序内部进行埋点,然后通过端点将指标暴露出去;有些服务不能够埋点,是一个黑盒(例如 Redis),Prometheus可以通过第三方的 Exporters,这些 Exporters 可以将这些服务内部的 Metrics 抓取出来并暴露给 Prometheus拉取。
(3)在架构图的左上角,对于有些系统,不能通过拉的方式去获取 Metrics,例如一些周期性运行的 Job。对于这些系统(Short-lived jobs),Prometheus 提供了 Push 网关,我们需要在这些任务内部将 metrics 数据主动 Push 到 Pushgateway。Prometheus再主动去 Pushgateway 拉取 Metrics。
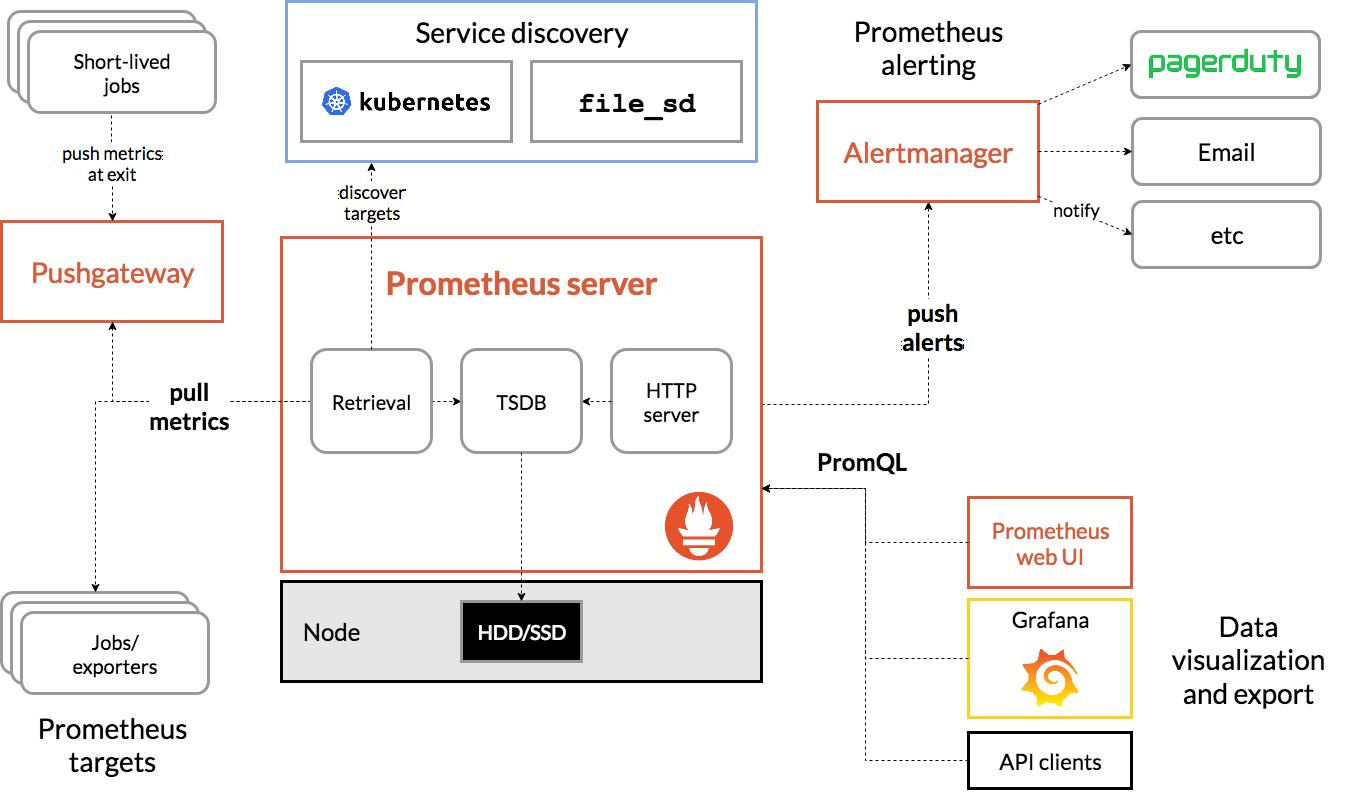
(4)在架构图的上方,介绍了 Prometheus如何去发现 Metrics 指标提供方暴露端点。对于 Push 模式的服务,Prometheus只需要去 Pushgateway 拉取即可;对于 Pull 模式的服务,支持静态配置(例如指定服务 IP/Port 等)和服务发现(例如 K8S 等)两种模式。
(5)在架构图的中央,介绍了 Prometheus 的核心组成模块。Retrieval 可以认为是一个 Job,它负责去发现暴露的端点,并去拉取数据。将数据存储在 TSDB 中,并持久化到本地。同时提供一个 HTTP Server,来查询 TSDB 中的数据。
(6)在架构图的右下方,Prometheus定义了一套 TSDB 的查询语法,称为 PromQL,全称为 Prometheus Query Language。通过 Prometheus 自己的 Web UI,或者是 Grafana,或者 Prometheus 提供的 API,就能够对 TSDB 数据进行查询和展示。
(7)在架构图的右上方,介绍了 Promethus 的告警模块。我们可以配置自定义的 Metrics 告警条件,当达到触发的阈值时,就会将告警信息 Push 到告警模块。告警模块本身并不产生告警信息,它接受到告警信息后,对信息进行分组、去重、路由(Emial、微信等)。
2.2 Metrics 种类
Promethues 支持以下四种 Metrics 种类:
(1)Counter 计数器:特点是自增的,适合用于统计接口请求数、下单数等。
(2)Gauge 测量仪:对当前值的一次快照,这个值可增可减,适合用于统计在线用户量等。
(3)Summary 汇总:在客户端计算,根据样本统计出百分位。例如统计链路耗时,TP99 是多少,TP95 是多少等。
(4)Histogram 直方图:通过分桶(bucket)的方式来统计样本的分布。比如统计接口的耗时,多少的请求落在 10ms - 20ms,多少的请求落在 20ms - 30ms 等。
2.3 Metrics 示例
一个 Metrics 指标形如下面所示:
1 | # HELP http_requests_total Total number of Http requests made. |
- 指标名为:
http_requests_total - 指标类型为:
counter - 该指标打了两个 Label(Tag),分别是 code 和 path,对应的 Value 是 200 和 /status
- 指标数值为:8
三、Grafana
Grafana 是一款跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。支持 InfuxDB、Prometheus 等主流 TSDB 作为数据源,本系列将使用它作为 Promethues 的数据消费方。
下面列出它的一些特点,有兴趣的朋友可以看看。
(1)展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
(2)数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
(3)通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
(4)混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
(5)注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
(6)过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
 wechat
wechat- alipay






